Abstract
Overview of RoT framework: Inspired by the diffusion of ripples in physics, human creative thinking is abstracted into five propagation components. These components are mapped onto the RoT reasoning process in MLLMs.
Benchmark
Statistics
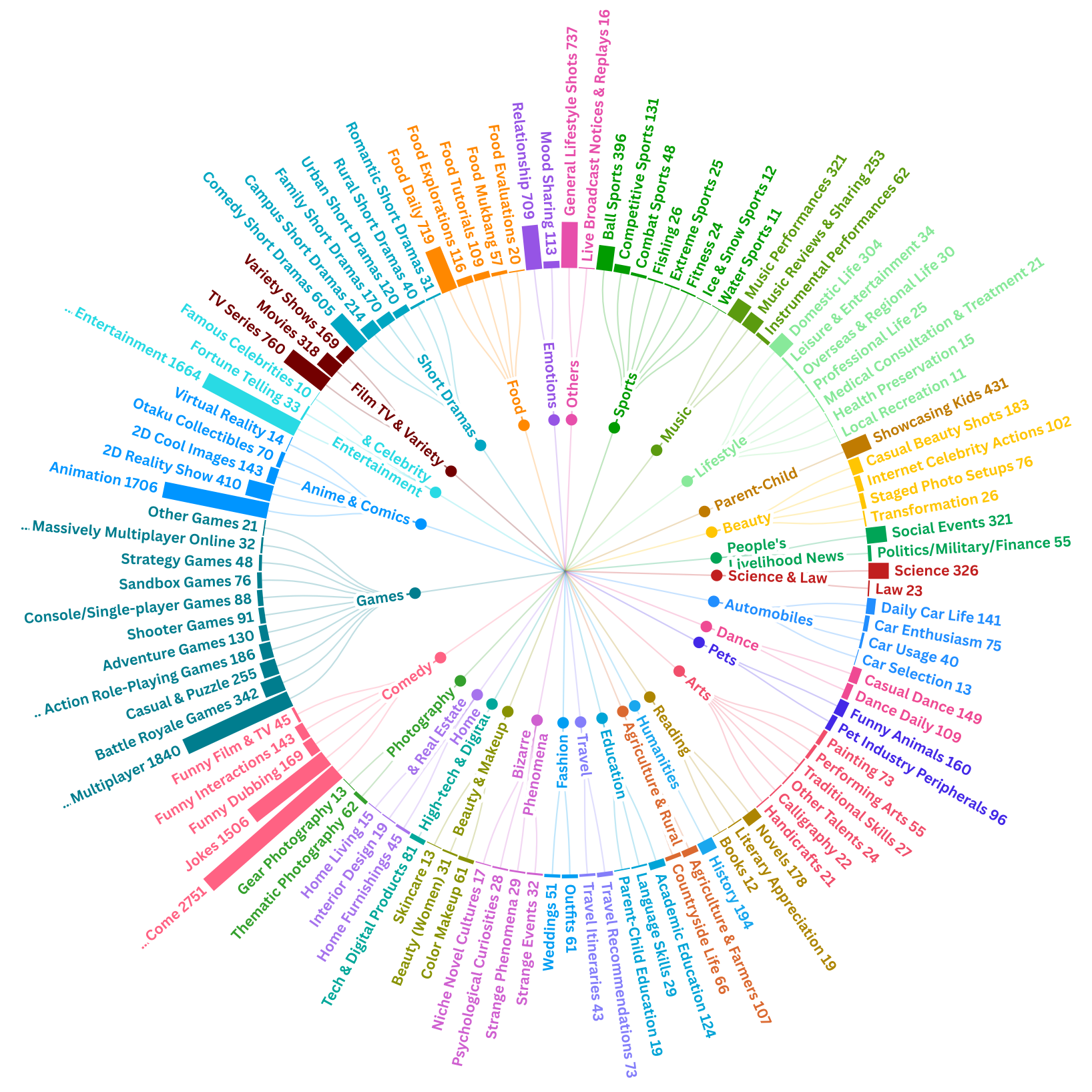

Composition and task distribution of GODBench: (Left) The dataset includes two main video categories—series videos and thematic videos—spanning 11 common themes such as Urban Life, Romance, Fantasy, and Food. Each series is annotated with its total number of videos. (Right) Task distribution is shown with detailed sample counts for each task defined in GODBench.
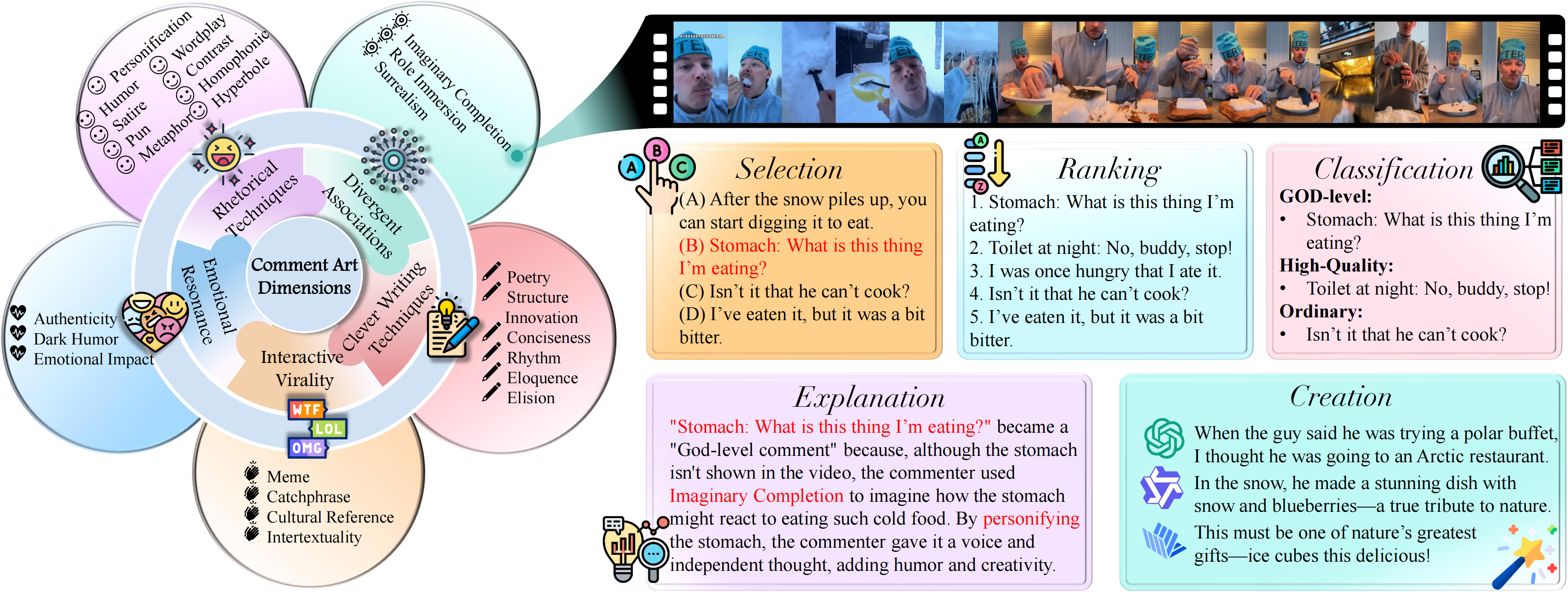
Comment Art taxonomy and example tasks: The figure defines five dimensions of Comment Art and presents an example from the “Imaginary Completion” category with associated tasks.
Dataset Comparison
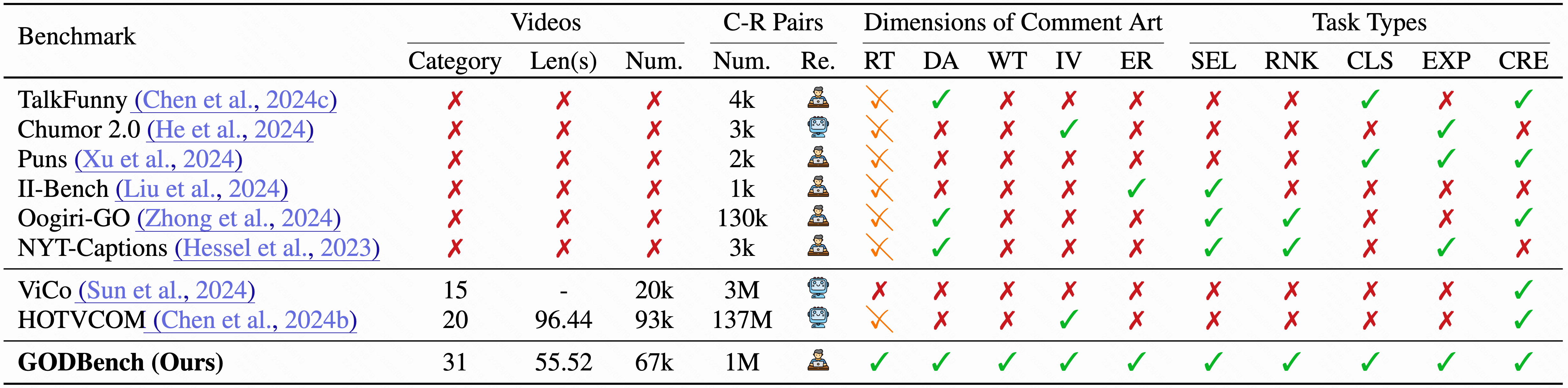
GODBench vs. existing benchmarks. Comparison includes video types, duration, context–response pairs with review type, coverage of five Comment Art dimensions (RT, DA, WT, IV, ER), and task types (SEL, RNK, CLS, EXP, CRE).
Examples of GODBench
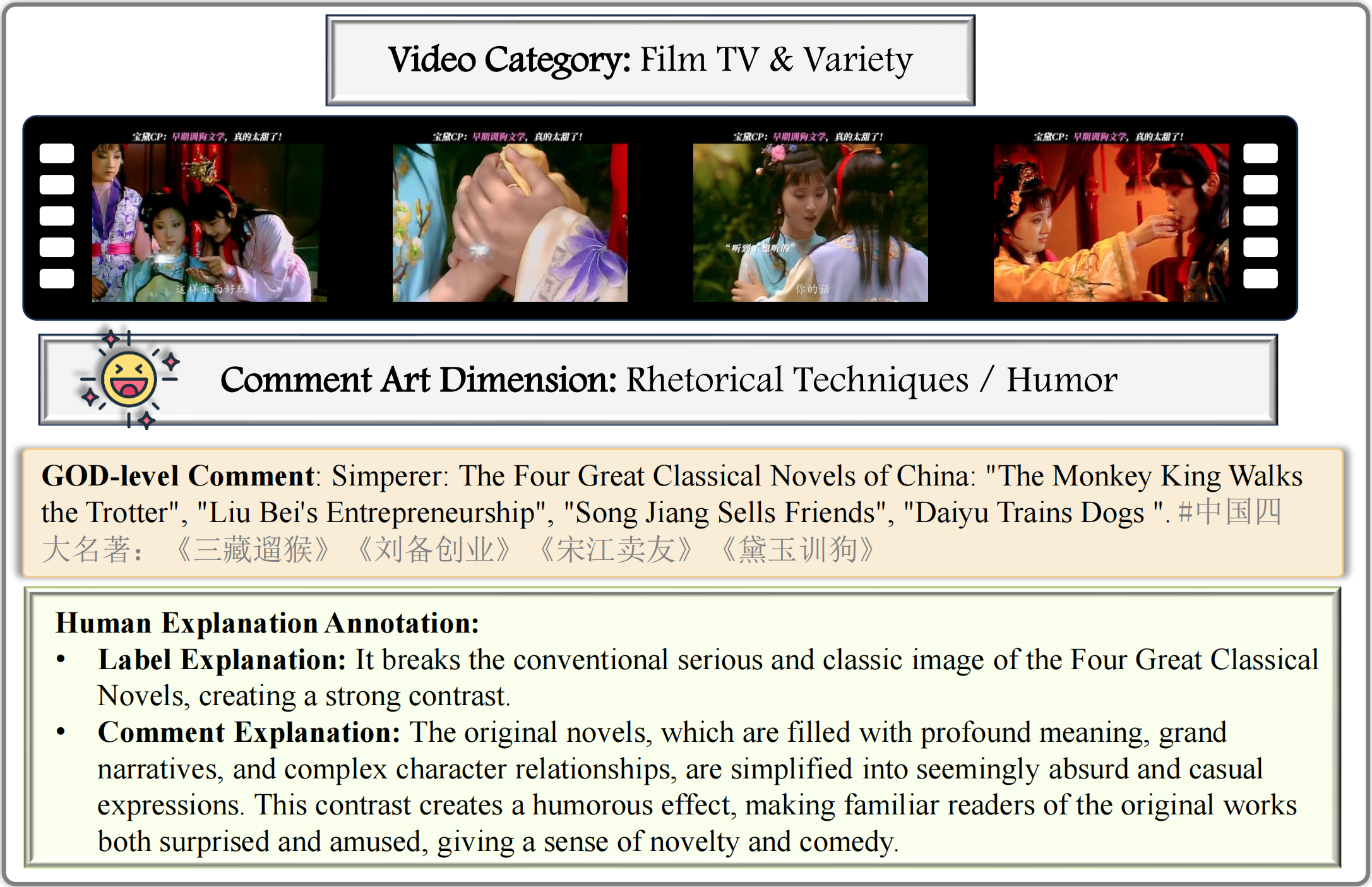

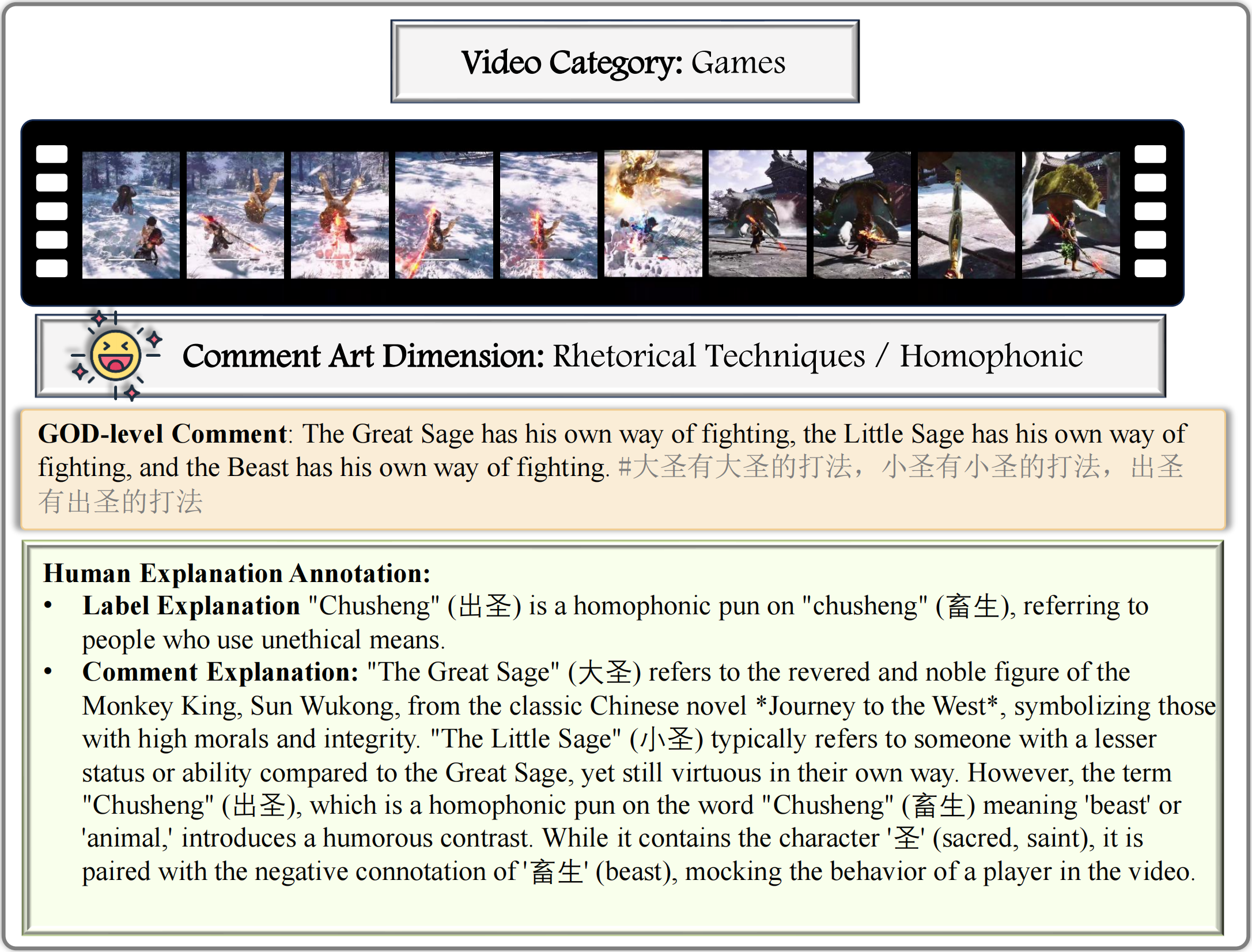












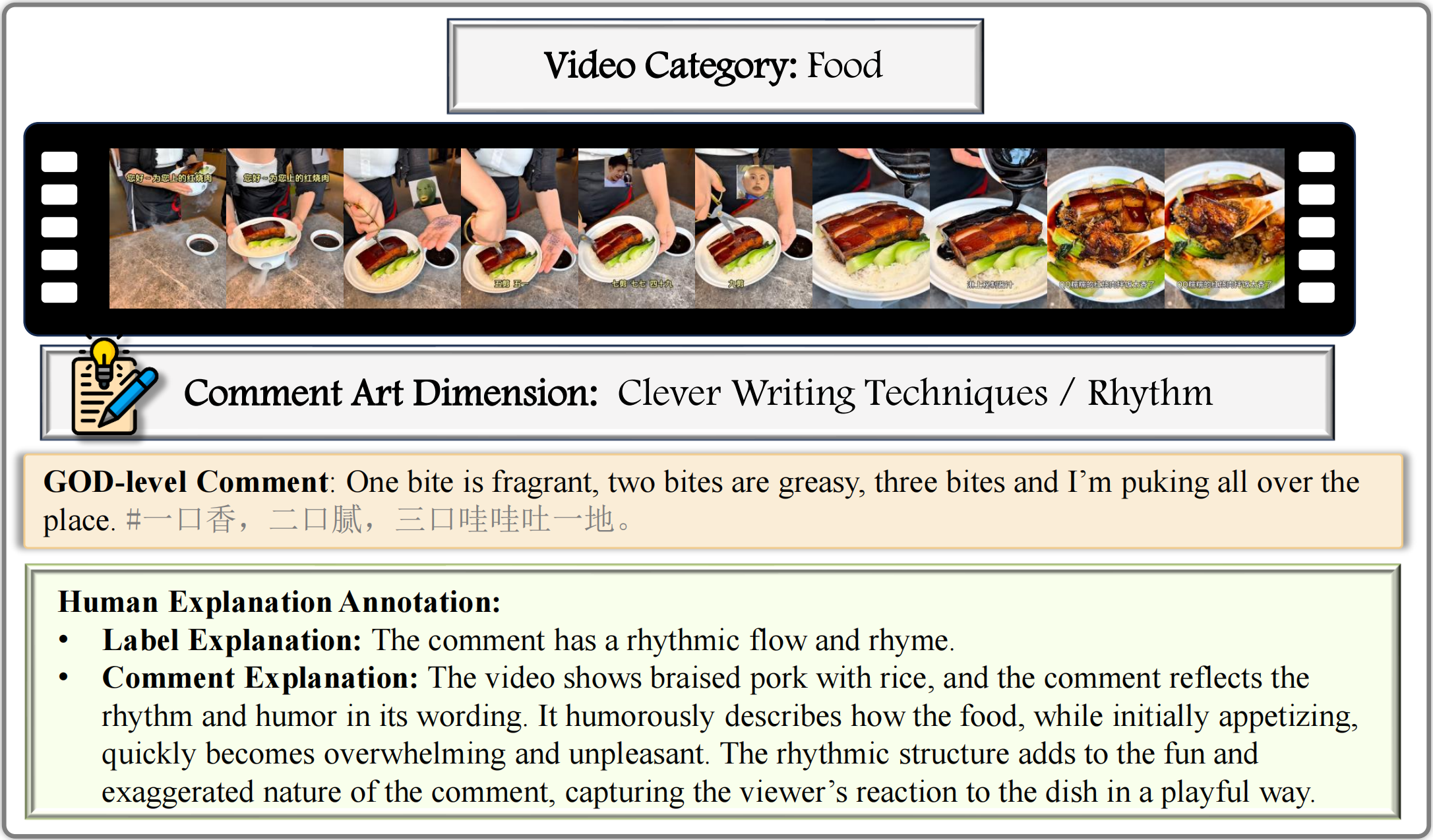







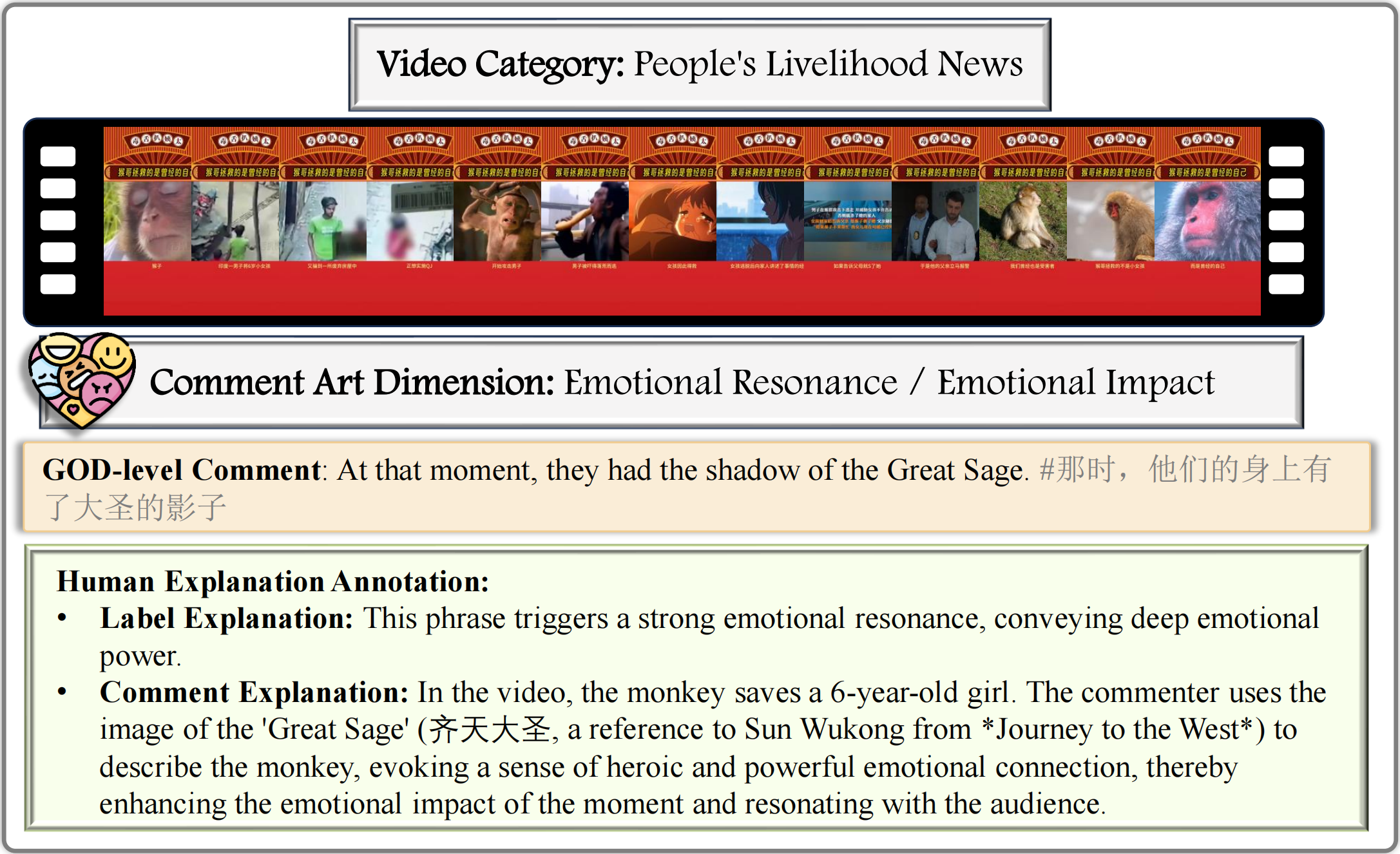
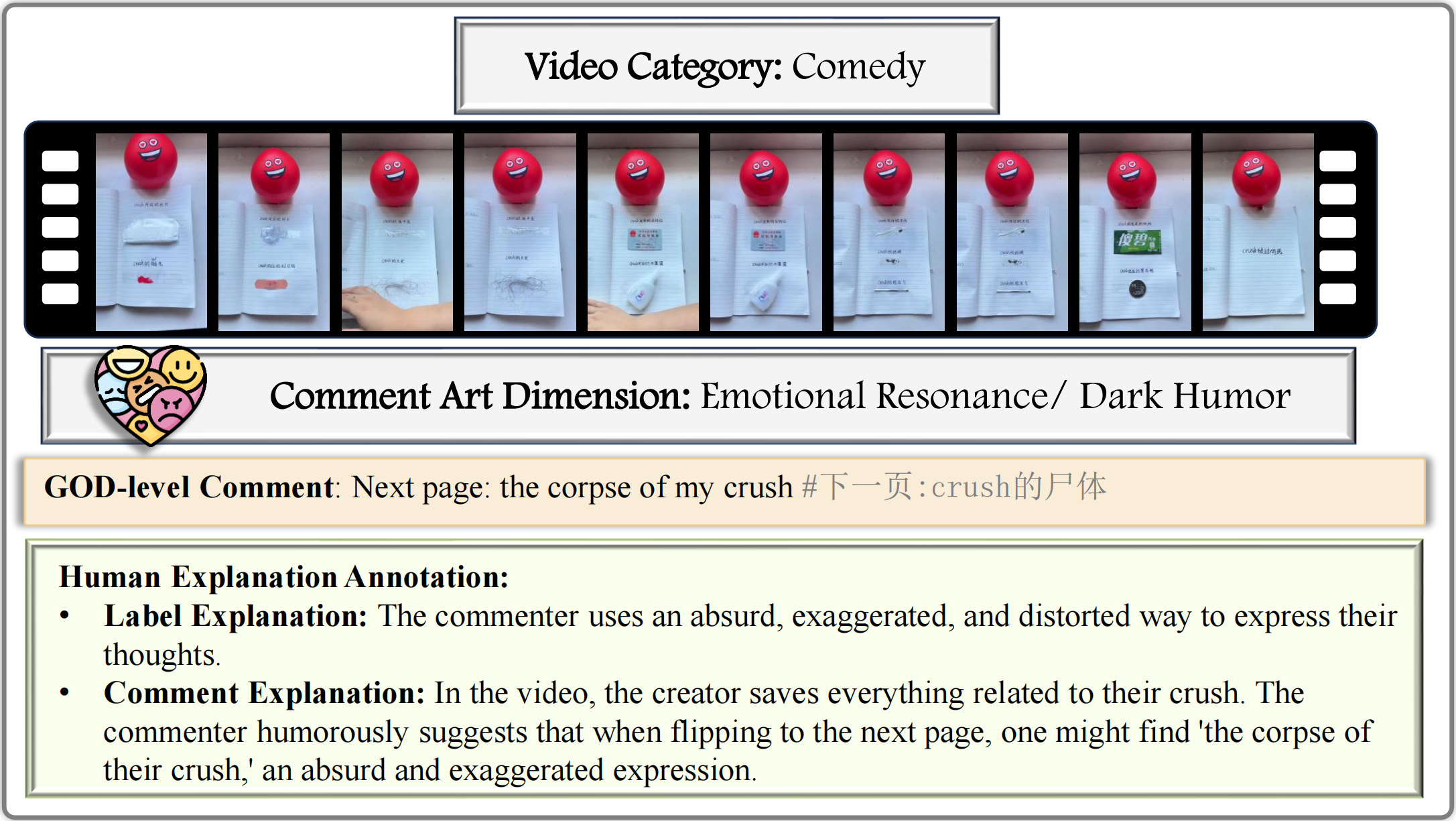
Examples from GODBench: We select one example for each of the 25 subcategories in GODBench, and all the samples are carefully annotated by human experts.
Evaluation
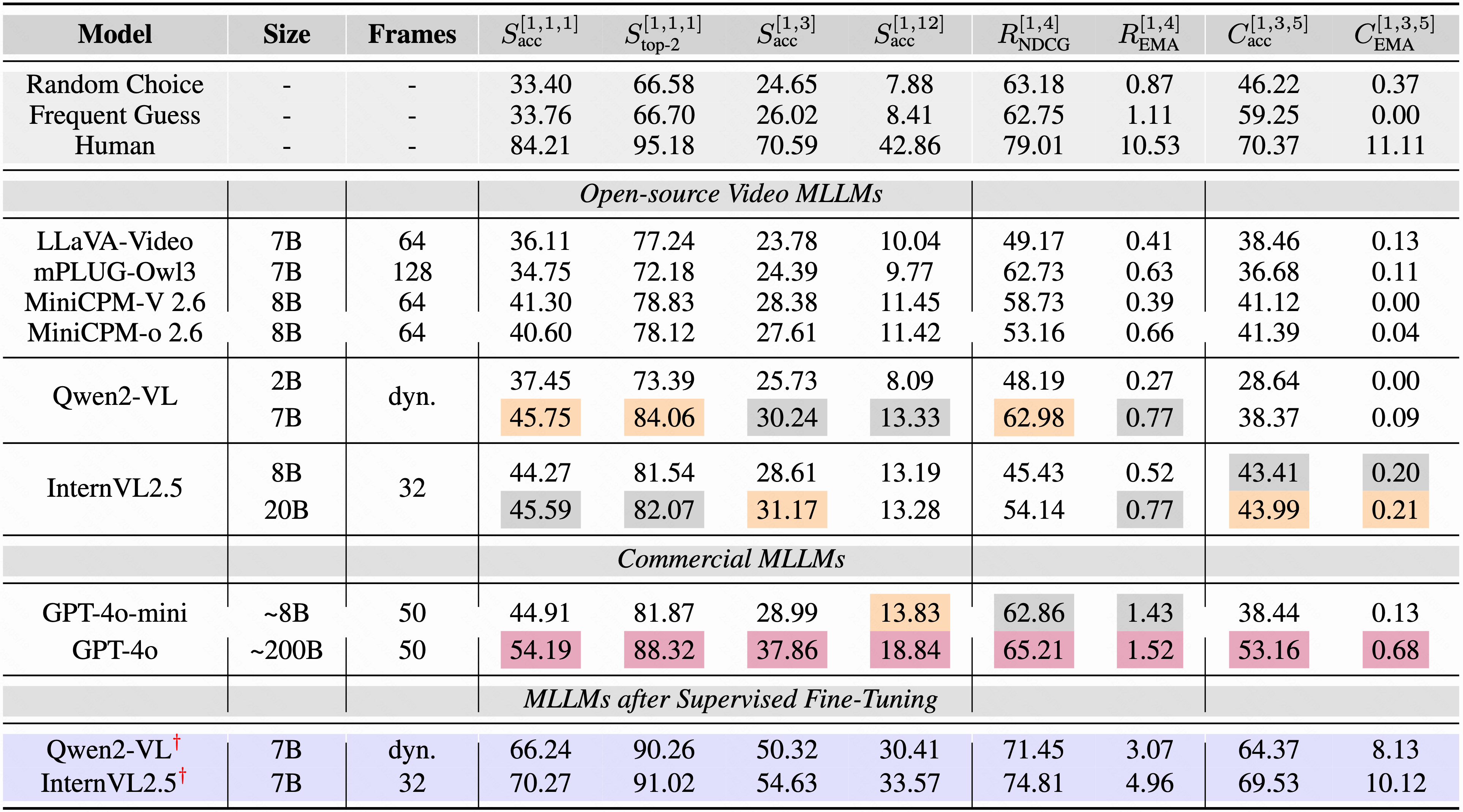
Performance of MLLMs on discriminative tasks: “Size” indicates the LLM size. Evaluation is based on Exact Match Accuracy (EMA), with results reported in percentage (%). † denotes models fine-tuned using LoRA. Top three scores are marked in purple, orange, and gray.
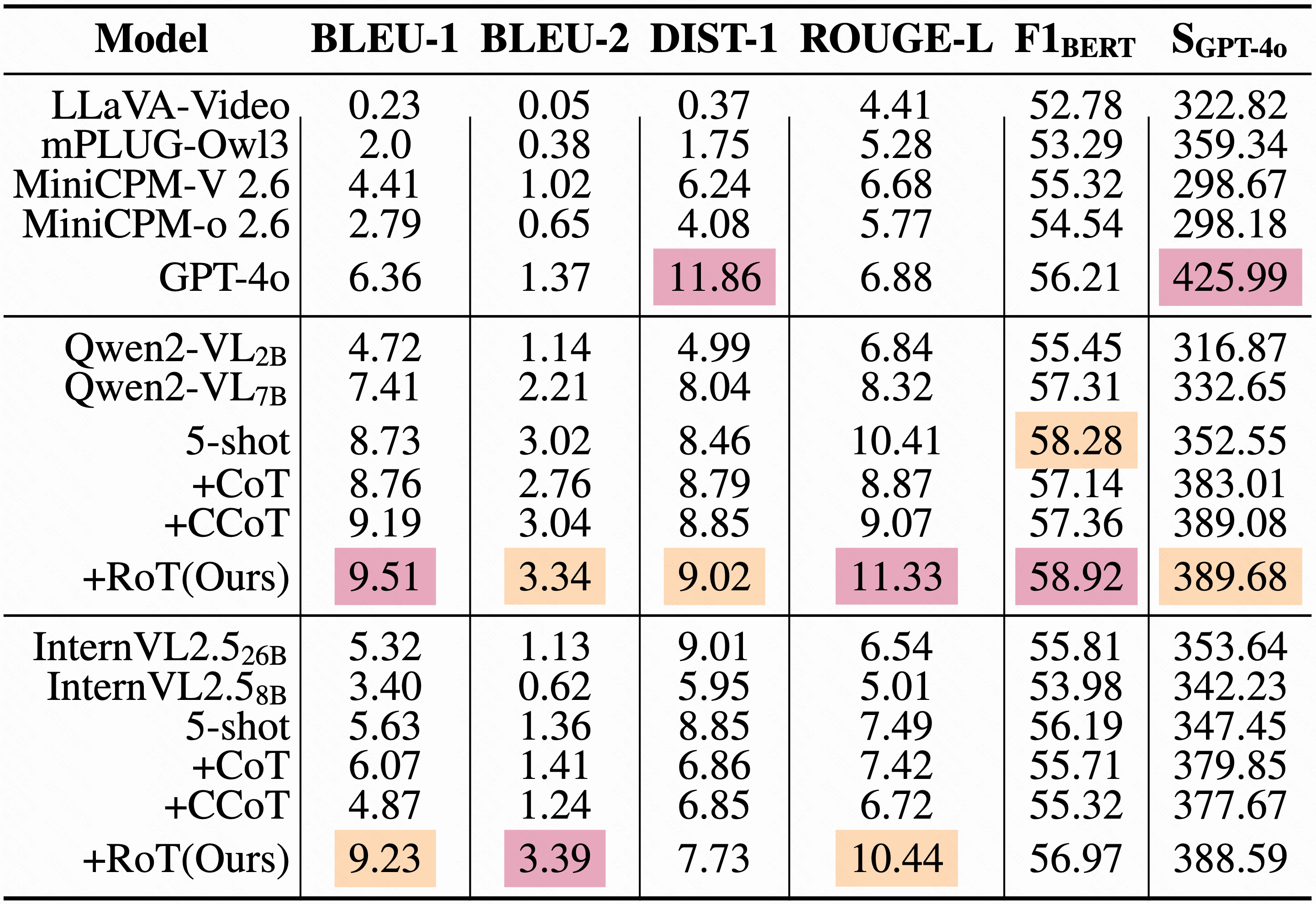
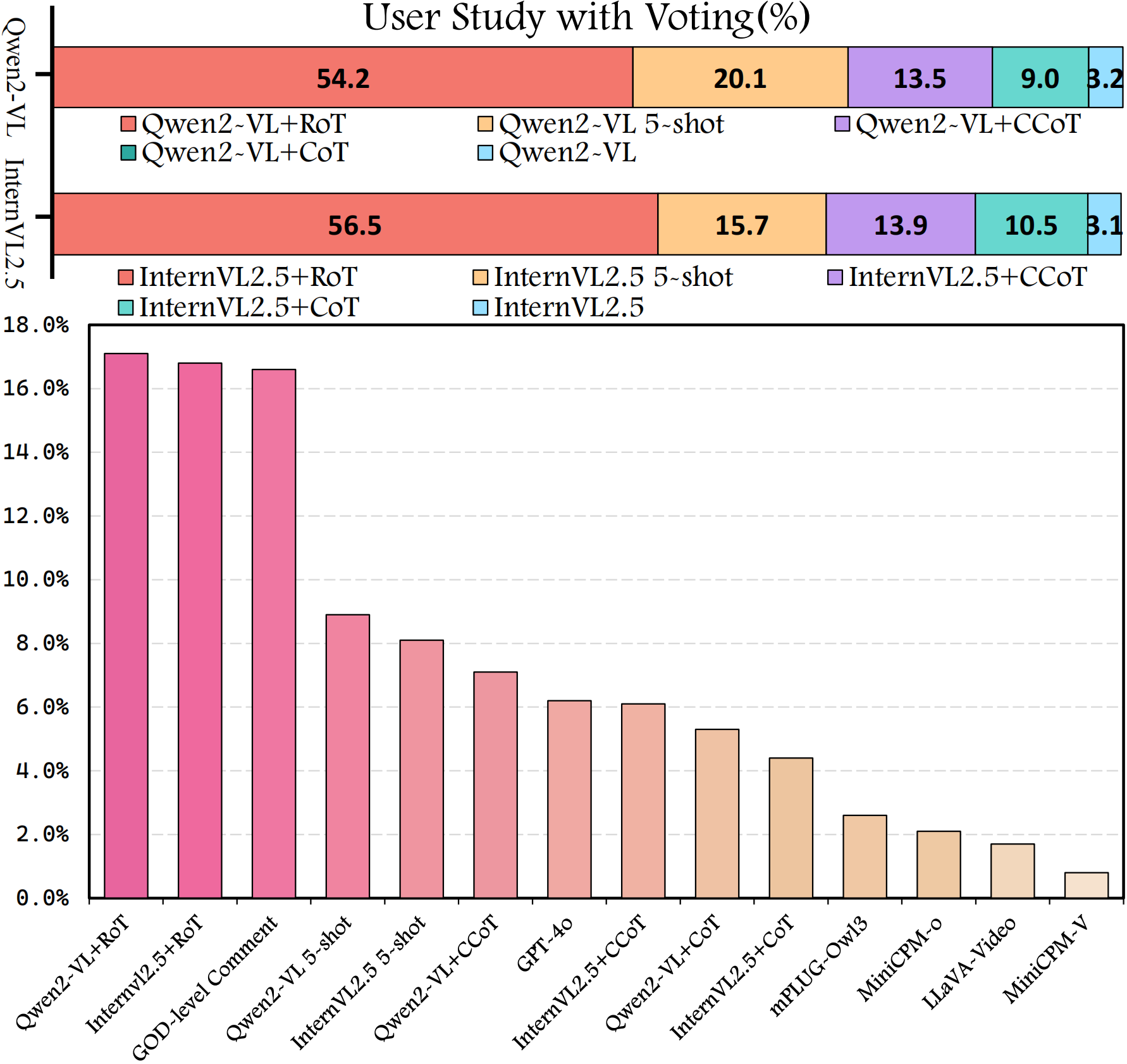
Performance of MLLMs on comment generation: Results are reported in percentage (%). “SGPT-4o” indicates quality scores evaluated by GPT-4o. A user study with voting (%) compares outputs from different models and improved methods.
Case Study
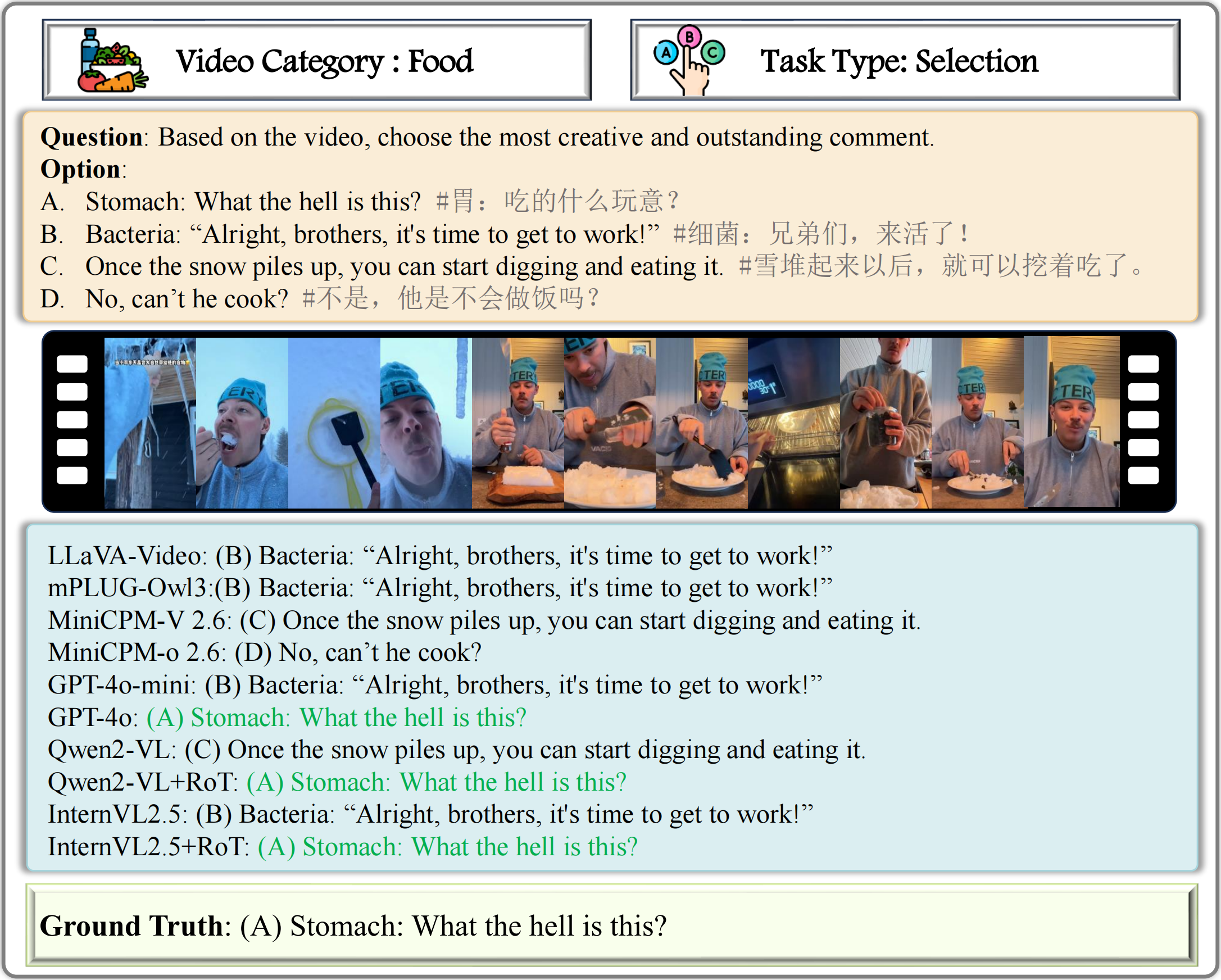
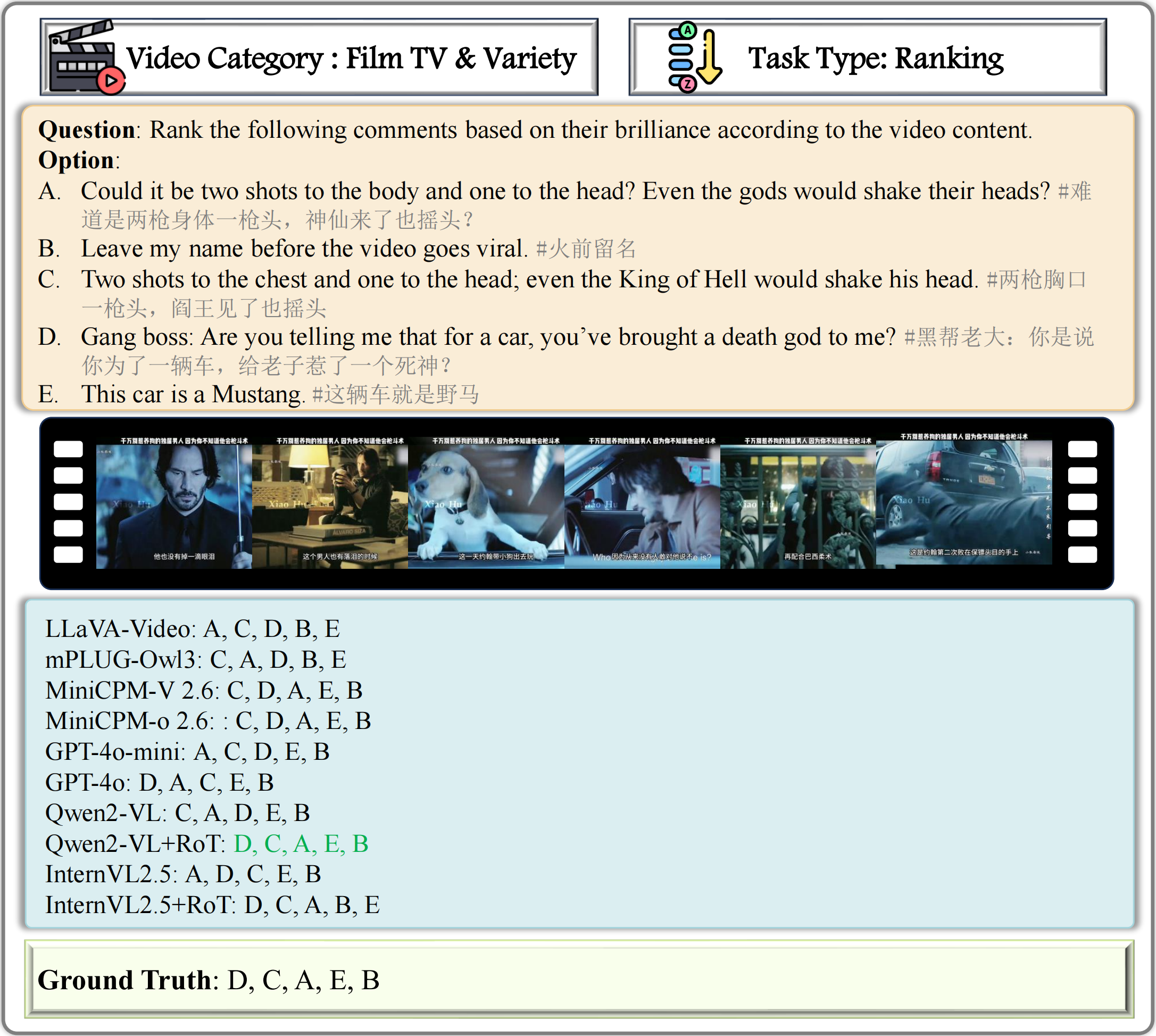







Case Study: We select 9 examples from GODBench to illustrate the performance of MLLMs on discriminative tasks and comment generation.
BibTeX
@misc{godbench2025,
title={GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art},
author={Yiming Lei and Chenkai Zhang and Zeming Liu and Haitao Leng and Shaoguo Liu and Tingting Gao and Qingjie Liu and Yunhong Wang},
year={2025},
eprint={2505.11436},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.11436},
}