Abstract
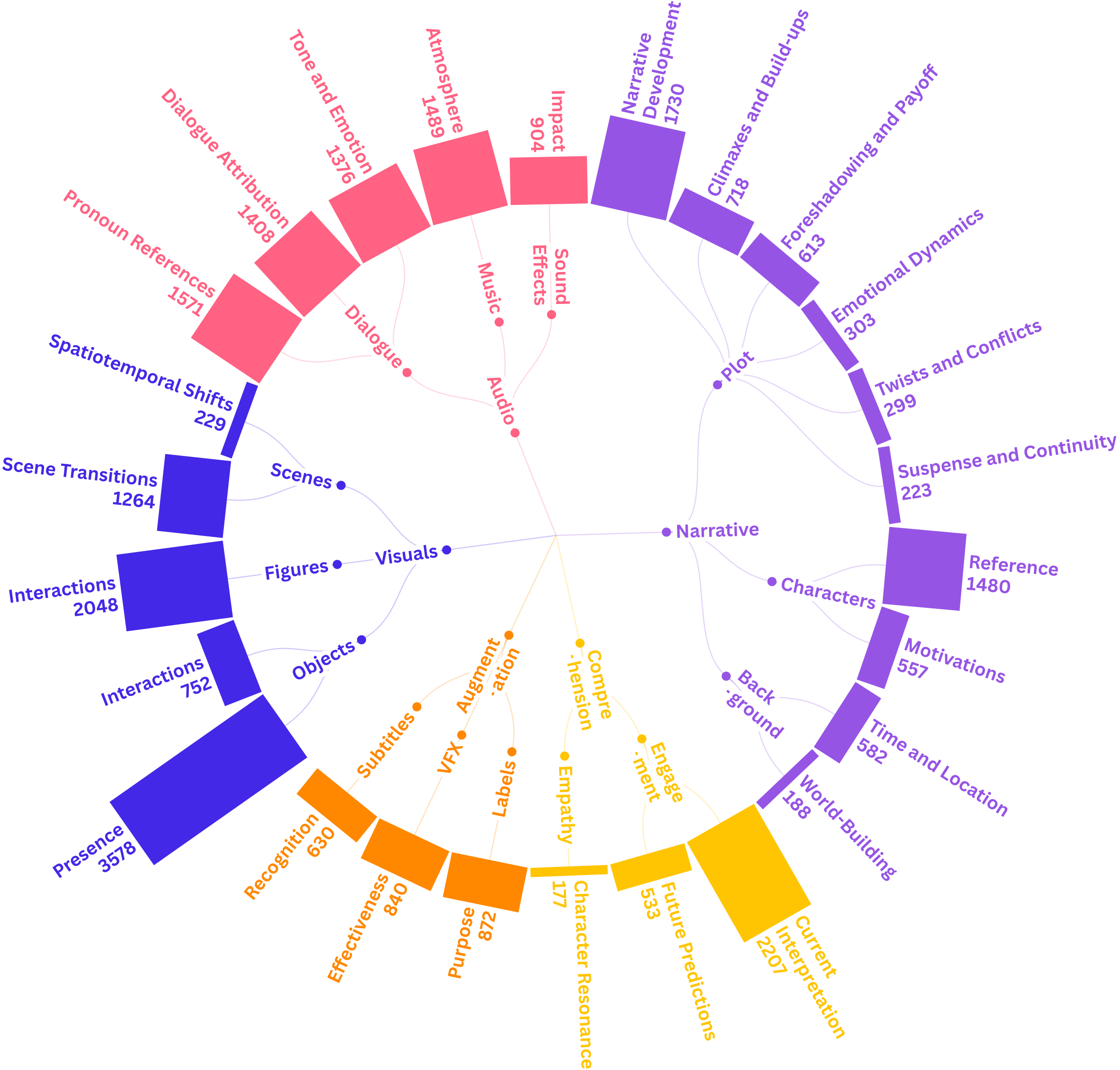
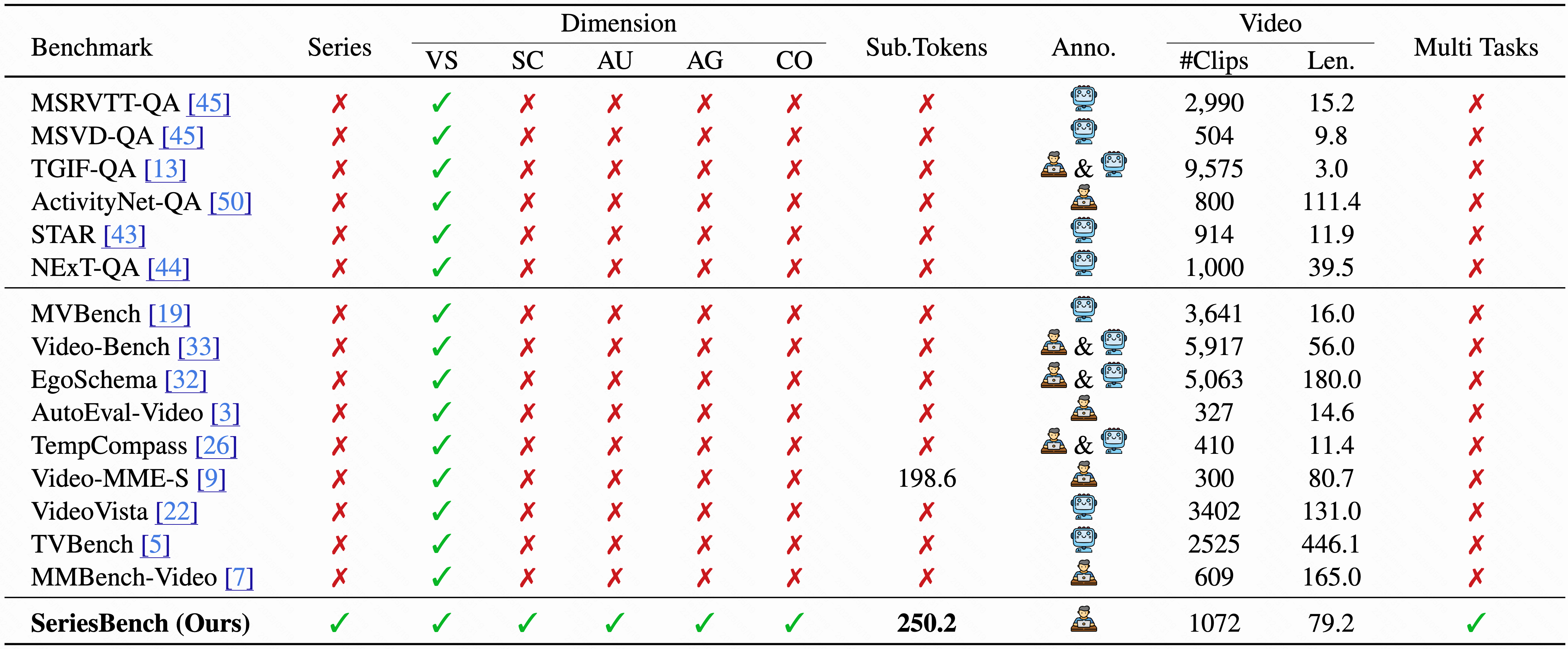
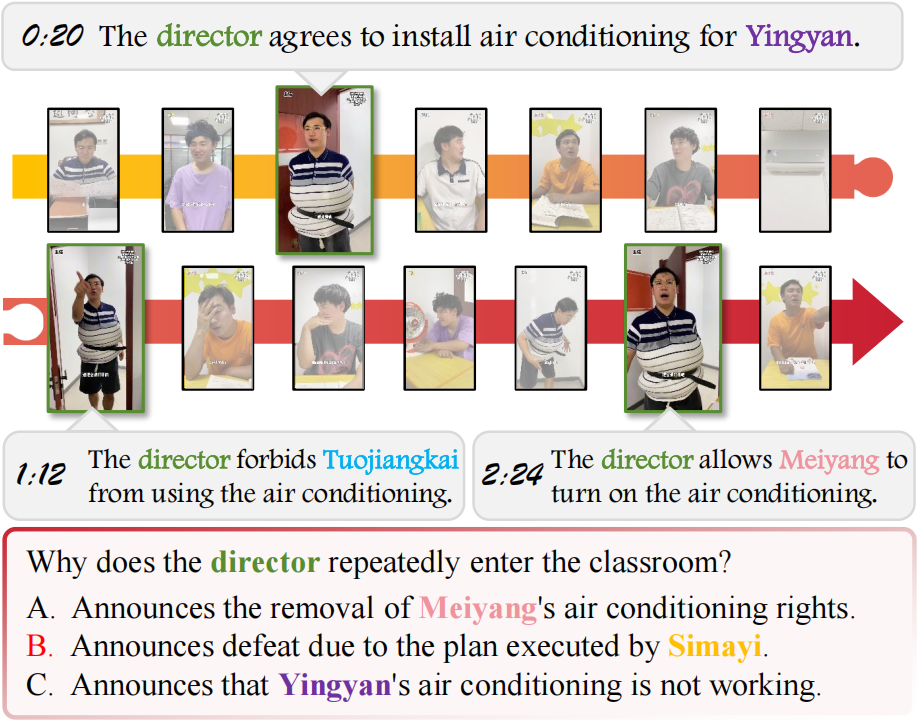
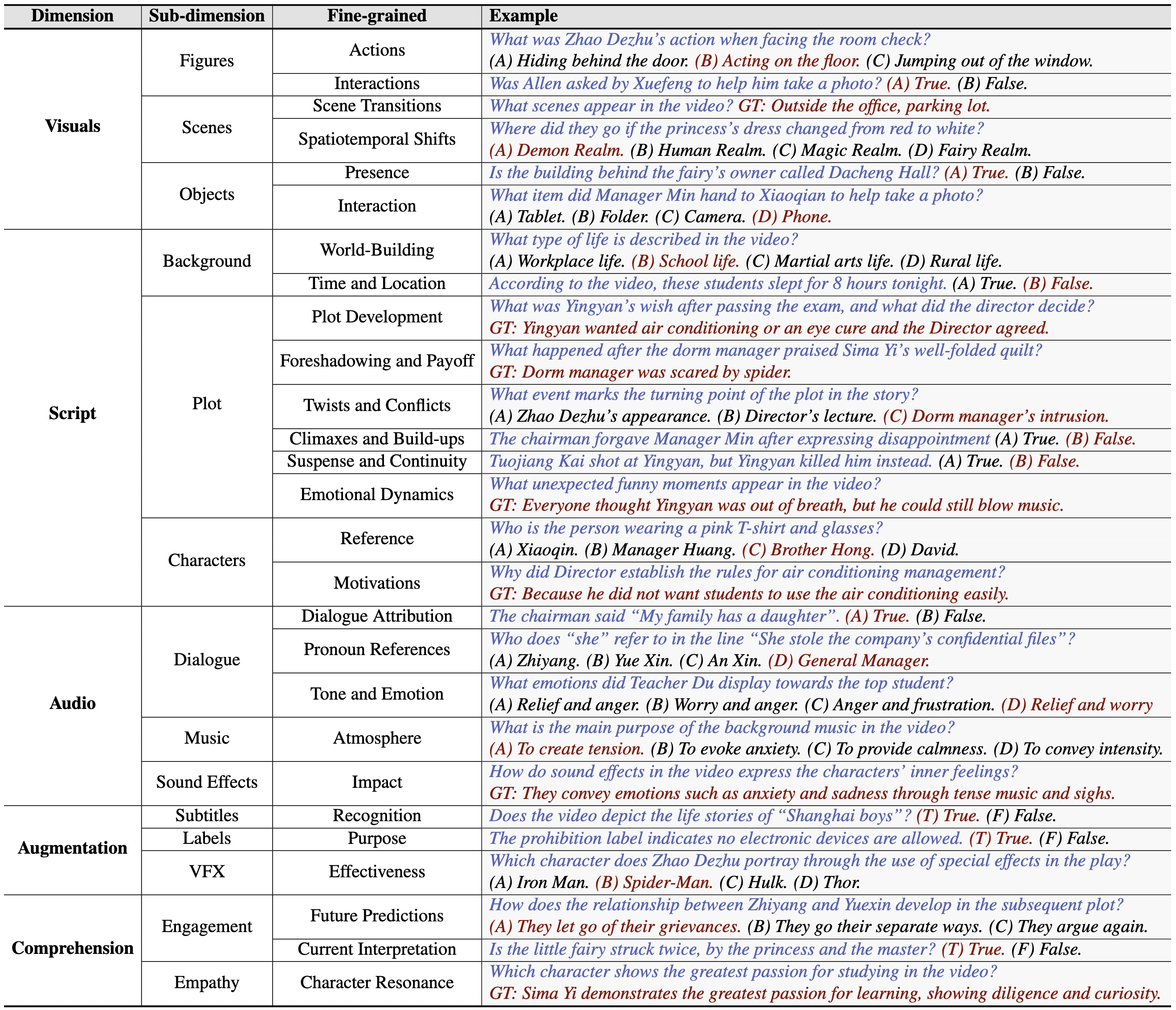
With the rapid development of Multi-modal Large Language Models (MLLMs), an increasing number of benchmarks have been established to evaluate the video understanding capabilities of these models. However, these benchmarks focus on standalone videos and mainly assess "visual elements" like human actions and object states. In reality, contemporary videos often encompass complex and continuous narratives, typically presented as a series. To address this challenge, we propose SeriesBench, a benchmark consisting of 105 carefully curated narrative-driven series, covering 28 specialized tasks that require deep narrative understanding. Specifically, we first select a diverse set of drama series spanning various genres. Then, we introduce a novel long-span narrative annotation method, combined with a full-information transformation approach to convert manual annotations into diverse task formats. To further enhance model capacity for detailed analysis of plot structures and character relationships within series, we propose a novel narrative reasoning framework, PC-DCoT. Extensive results on SeriesBench indicate that existing MLLMs still face significant challenges in understanding narrative-driven series, while PC-DCoT enables these MLLMs to achieve performance improvements. Overall, our SeriesBench and PC-DCoT highlight the critical necessity of advancing model capabilities to understand narrative-driven series, guiding the future development of MLLMs. SeriesBench is publicly available at our GitHub repository.
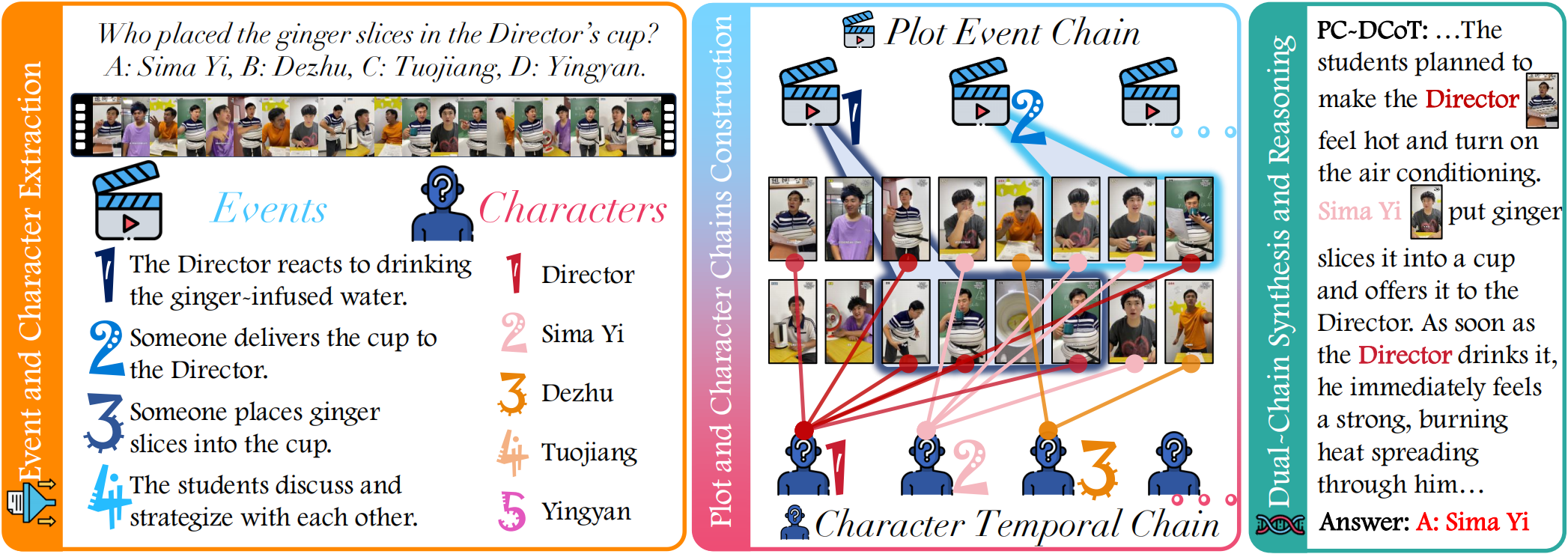
Overview of PC-DCoT framework: Event and character chains are constructed separately from the input, then merged to enable question answering via dual-chain reasoning.