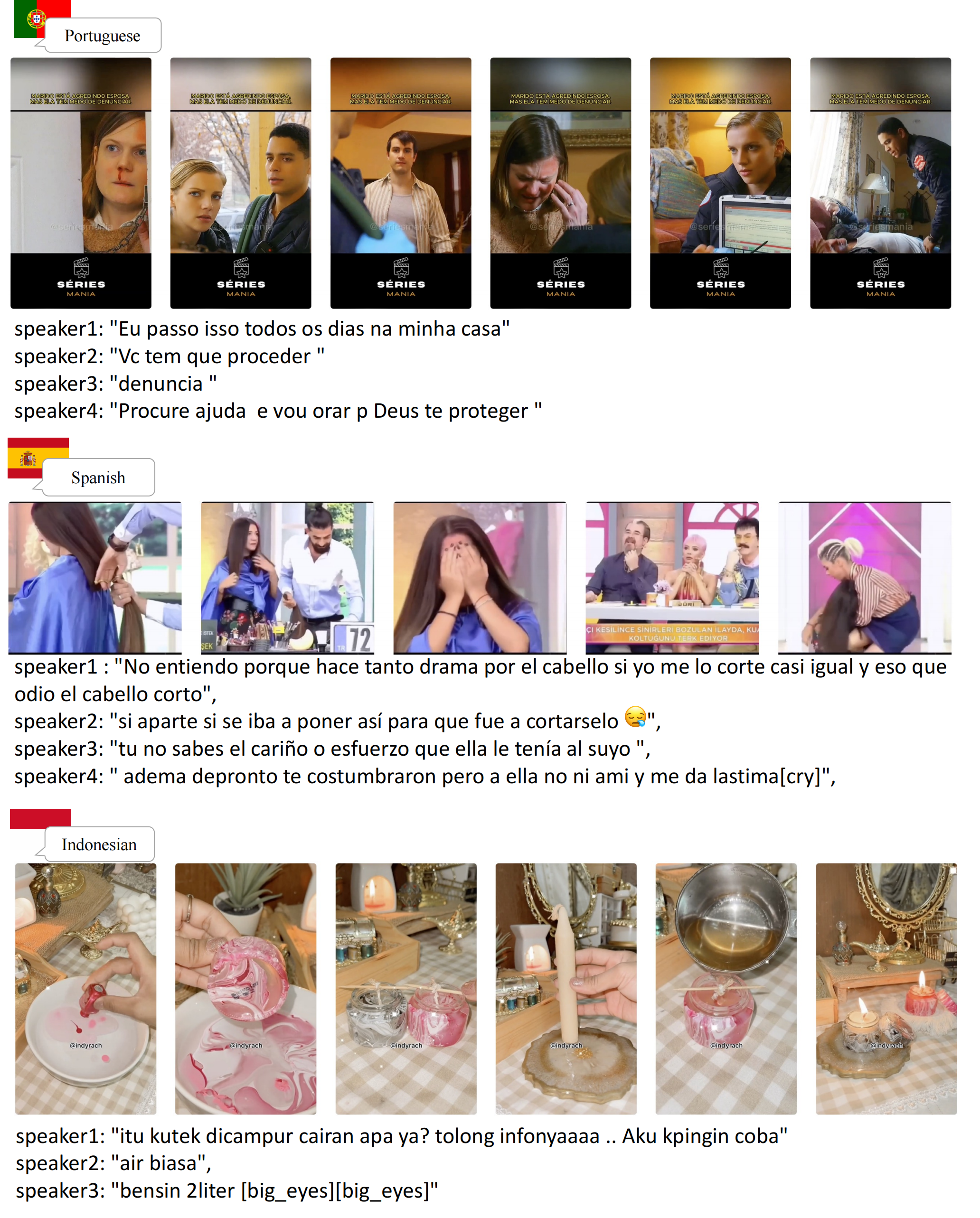
Abstract
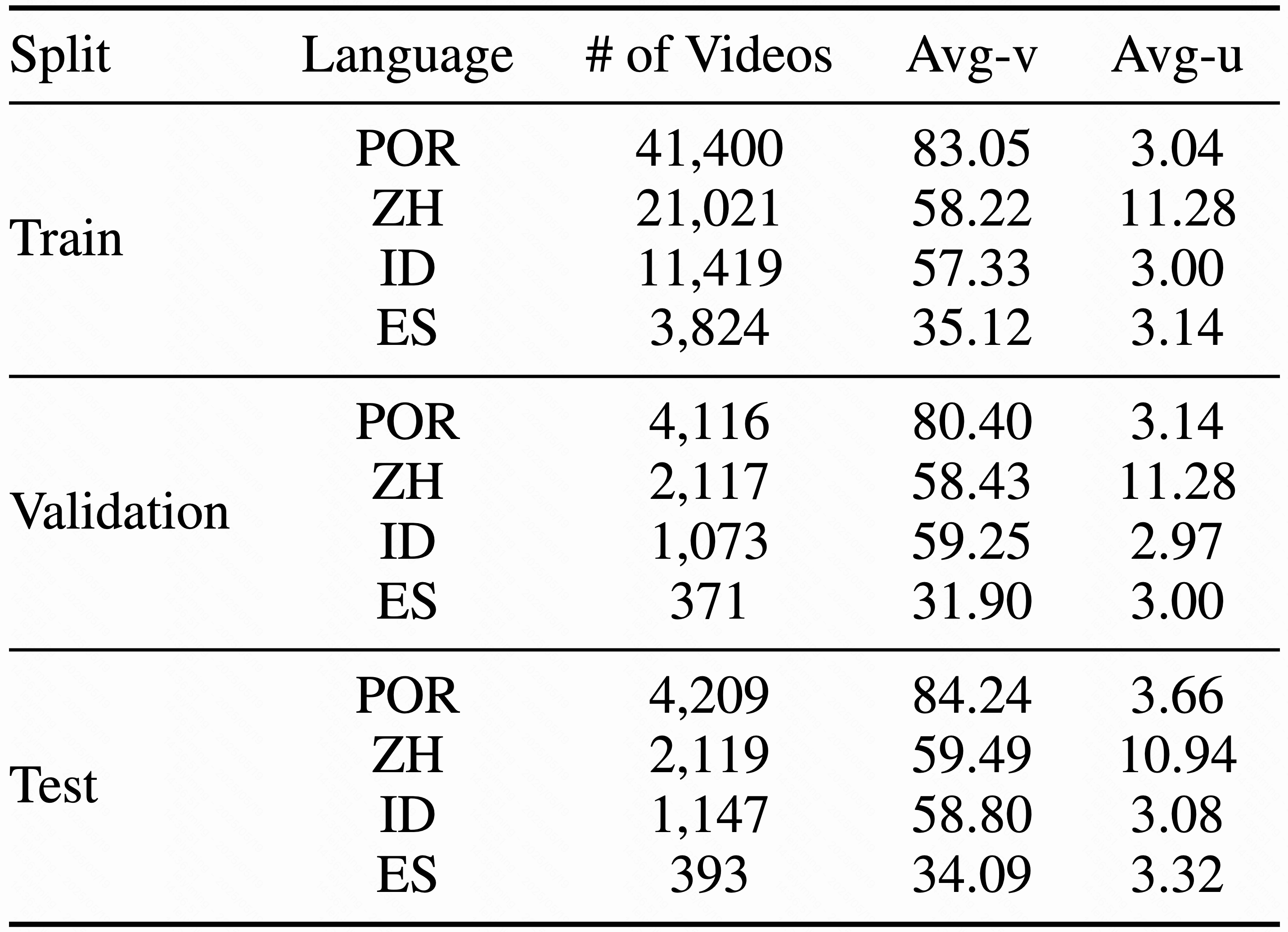
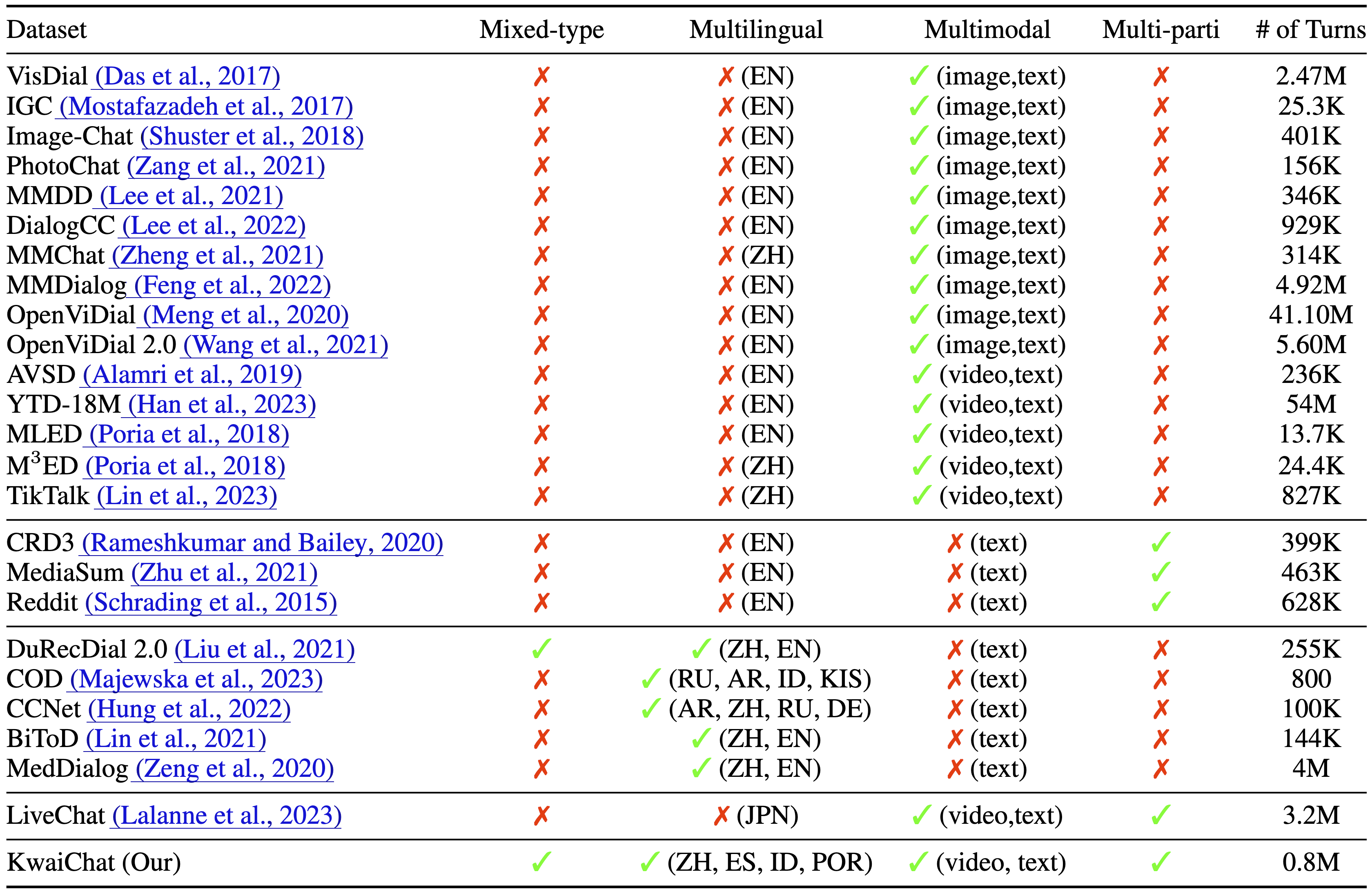
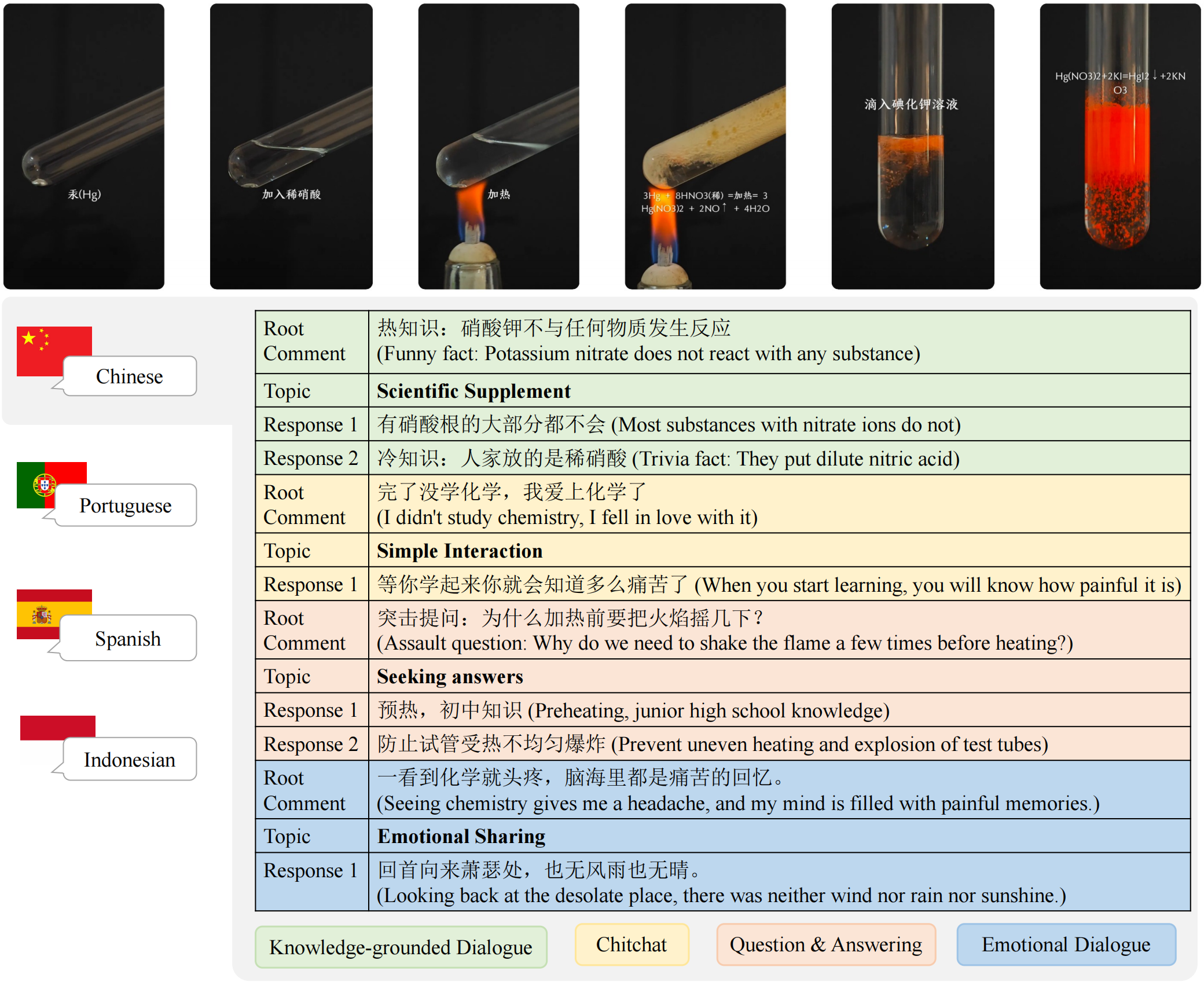
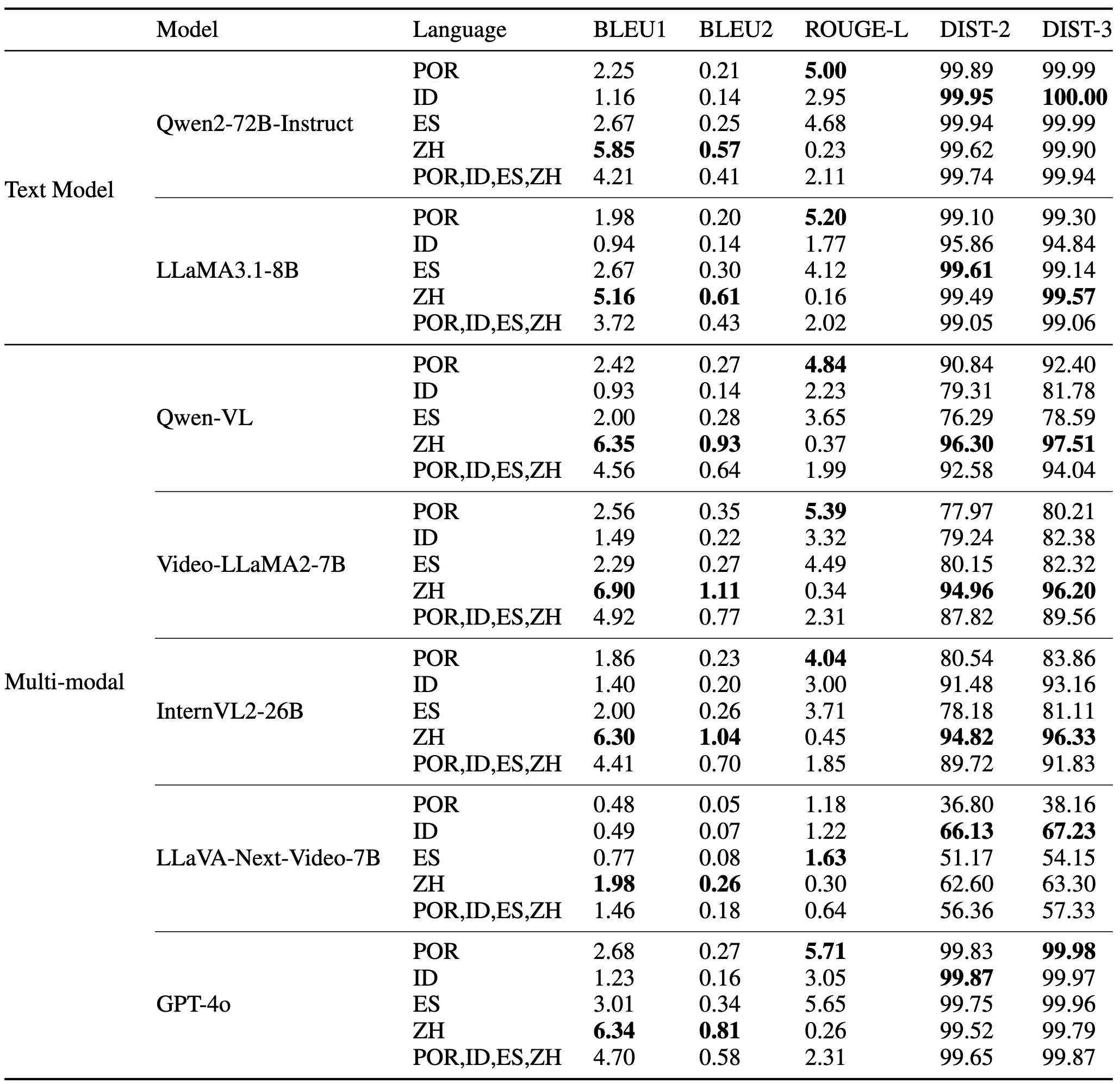
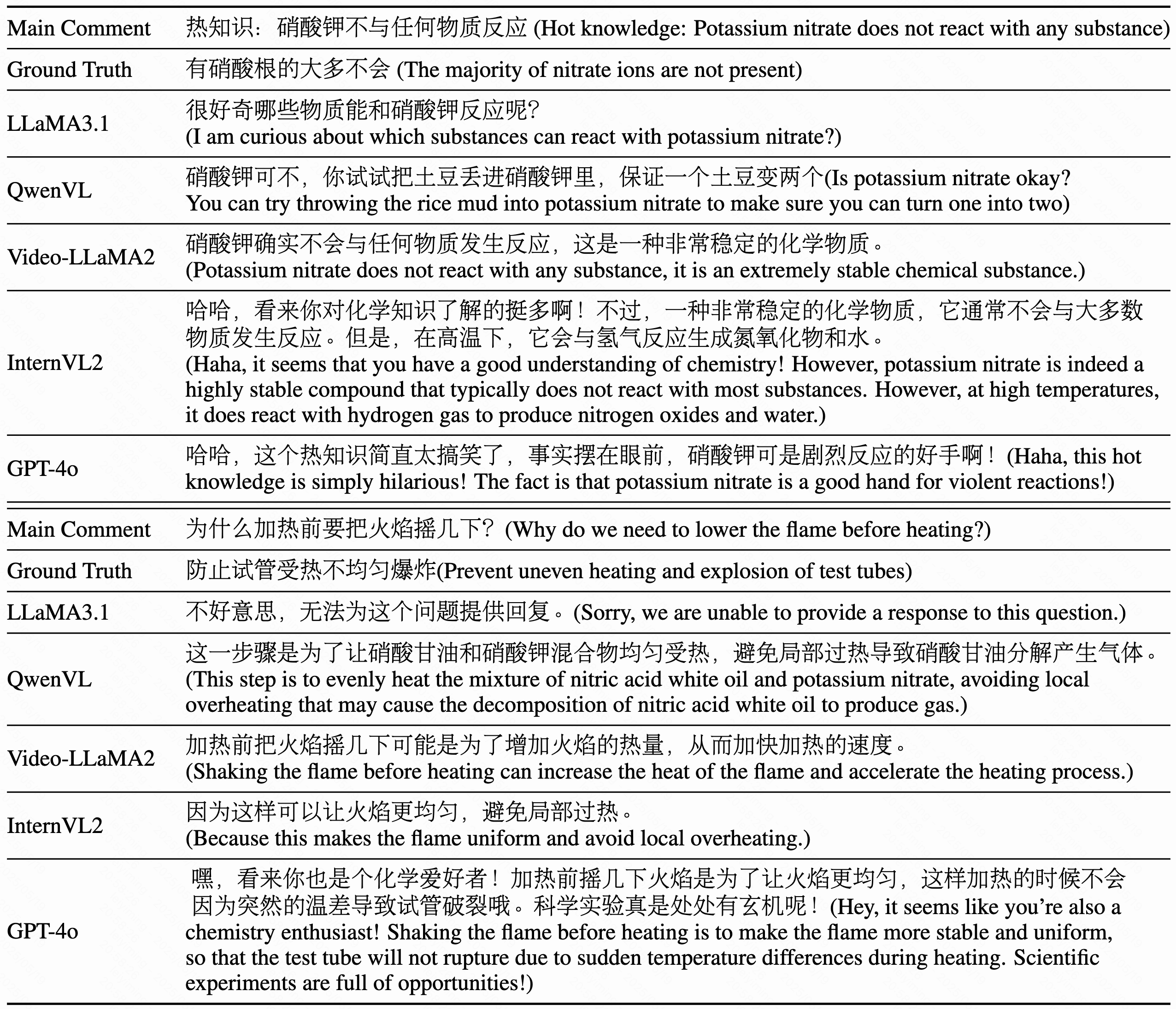
Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
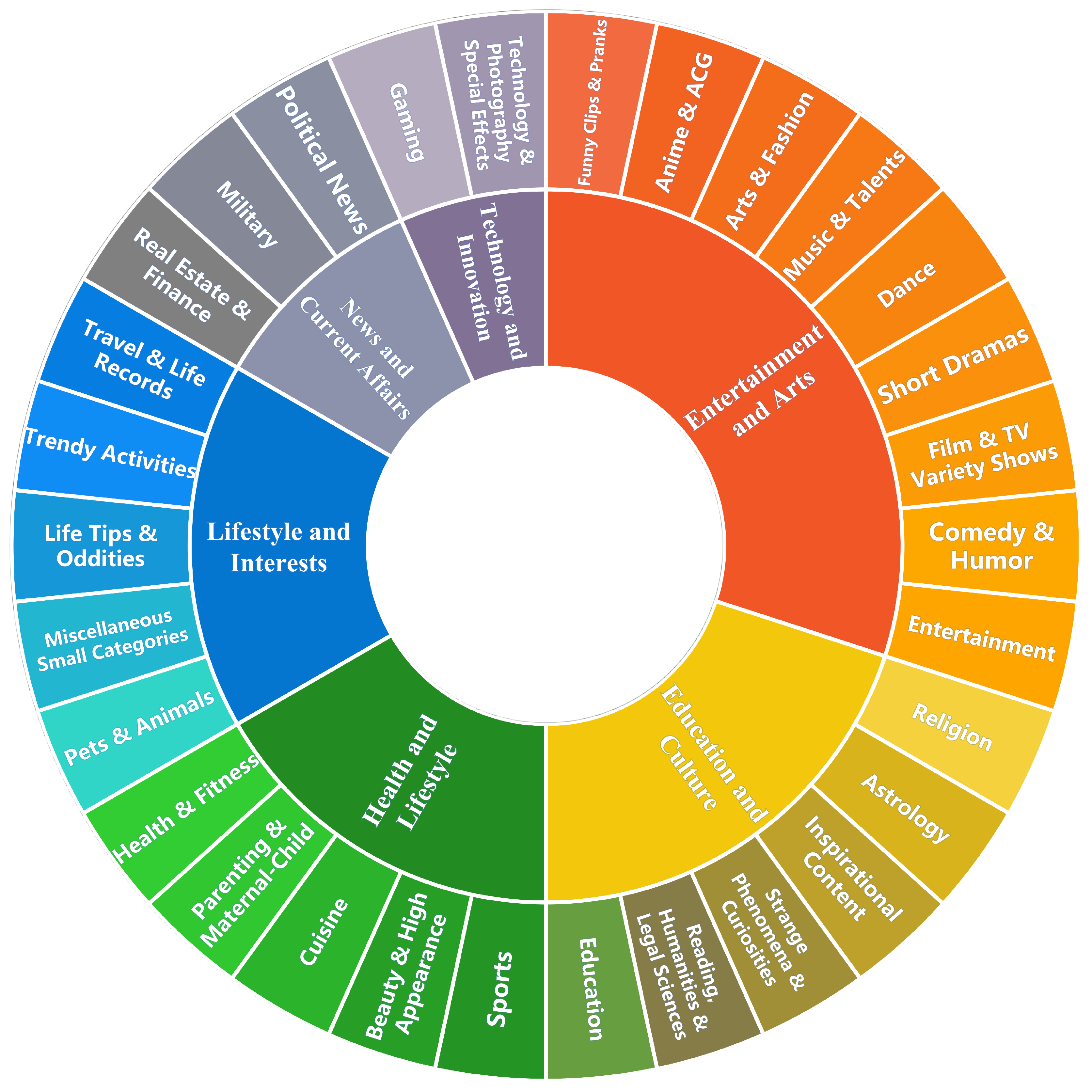
Dataset composition overview: Domains, languages, topics, and dialogue types with balanced distribution across categories in KwaiChat.