0 课程背景
- LMDeploy 量化部署 LLM-VLM 实践
- InternLM/Tutorial
- 主讲人:书生·浦源挑战赛冠军队伍队长,安泓郡
本节课主要介绍大模型部署的方法和LMDeploy框架的使用。
1 课程笔记
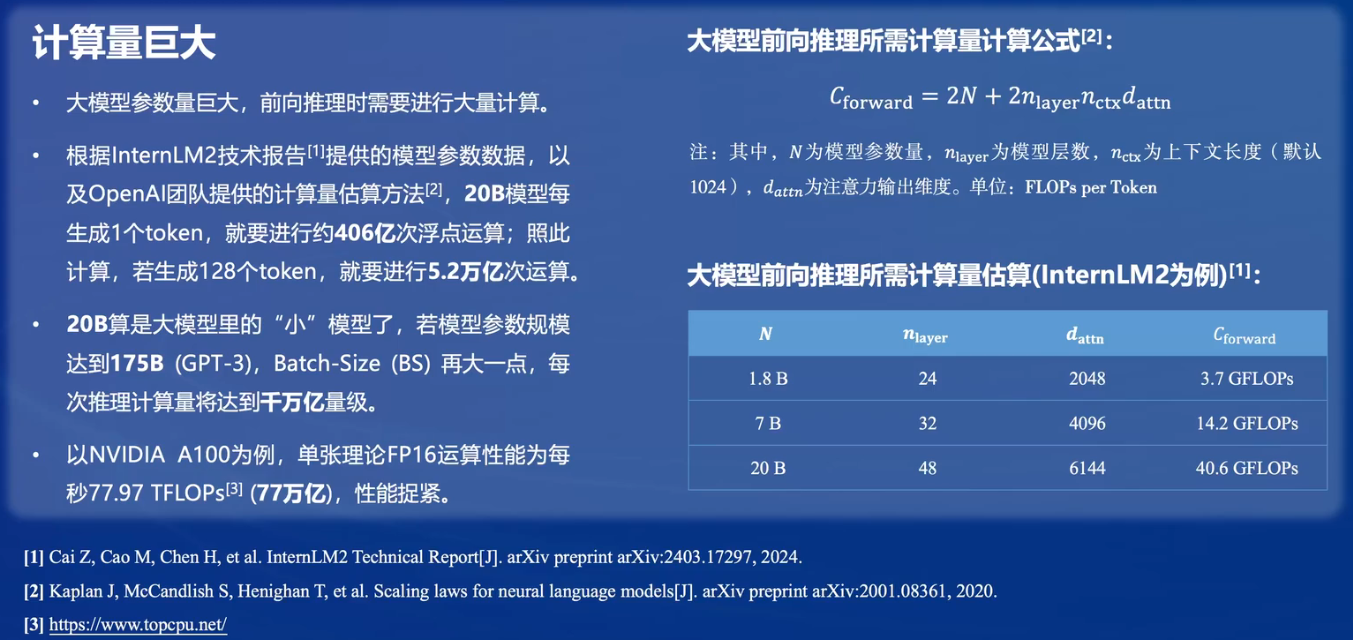
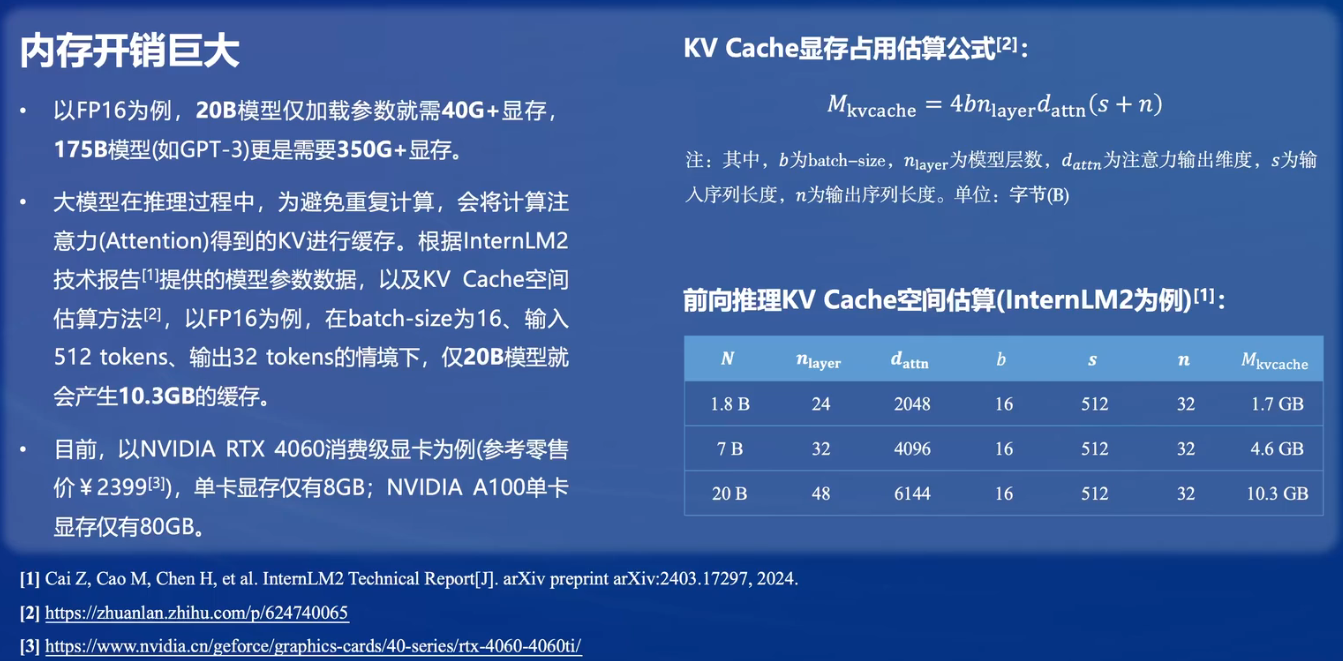
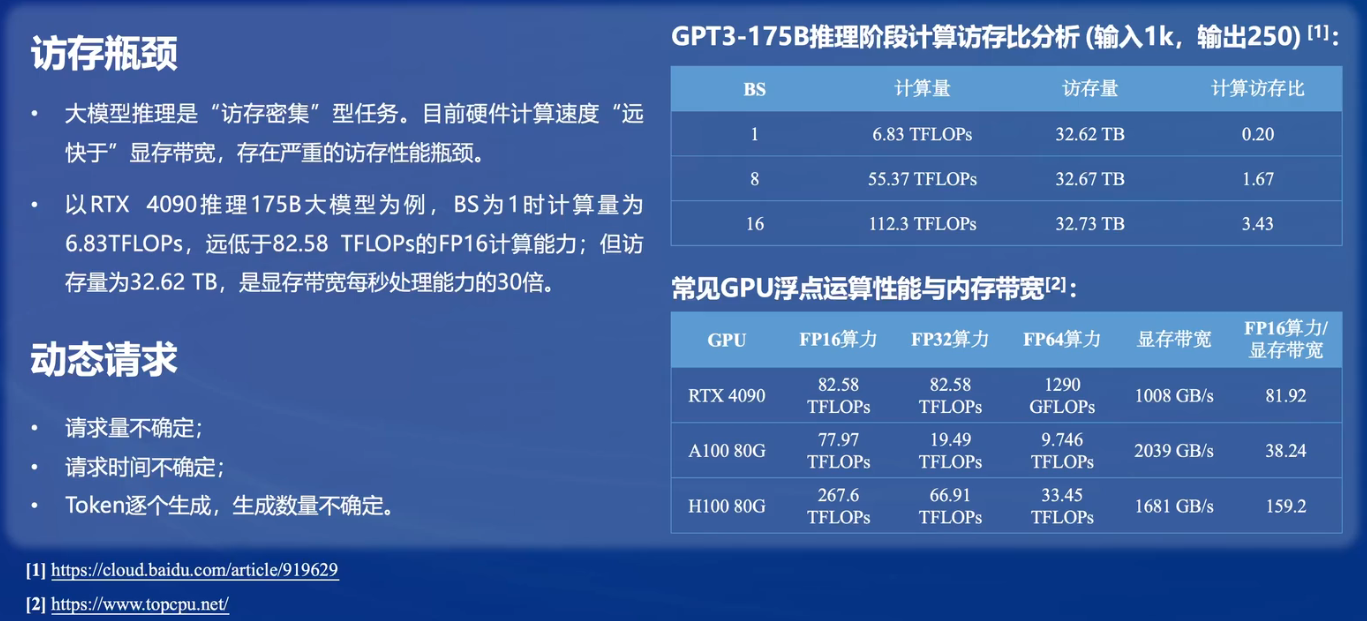
大模型部署的挑战
大模型部署方法
- 模型剪枝(Pruning)
- 知识蒸馏(Knowledge Distillation,KD)
- 量化(Quantization)



LMDeploy
- LMDeploy 由 MMDeploy 和 MMRazor 团队联合开发,是涵盖了 LLM 任务的全套轻量化、部署和服务解决方案。
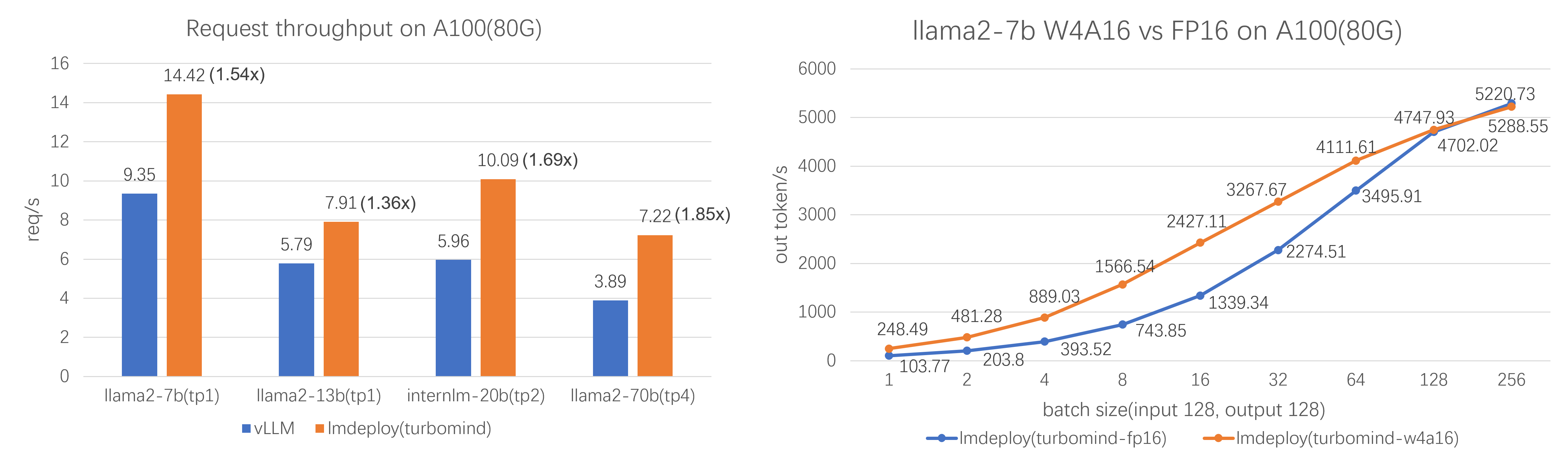
- 高效的推理:LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
- 可靠的量化:LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
- 便捷的服务:通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理:通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
- 性能
- 在各种规模的模型上,每秒处理的请求数是 vLLM 的 1.36 ~ 1.85 倍。在静态推理能力方面,TurboMind 4bit 模型推理速度(out token/s)远高于 FP16/BF16 推理。在小 batch 时,提高到 2.4 倍。
- 支持的模型
2 基础作业
环境配置
-
conda activate lmdeploy pip install lmdeploy[all]==0.3.0 -

-
使用transformer库进行推理
-
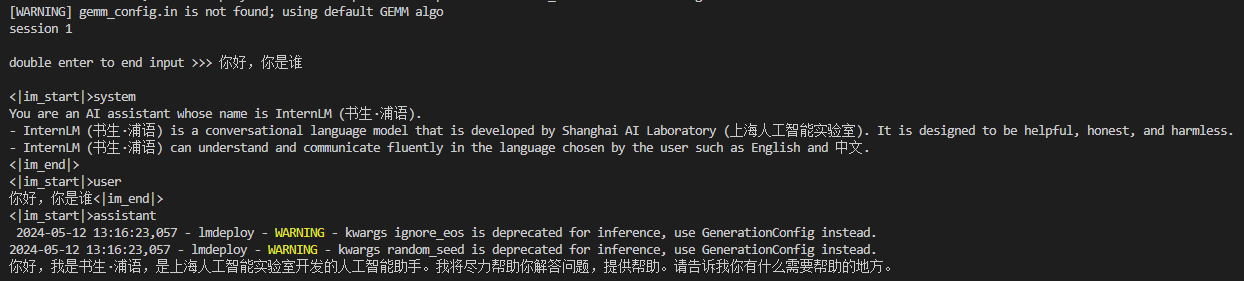
以命令行方式与InternLM2-Chat-1.8B 模型对话(推理速度明显快得多)