0 课程背景
- XTuner 微调LLM:1.8B、多模态、Agent
- InternLM/Tutorial
- 主讲人:XTuner贡献者:李剑锋,汪周谦,王群
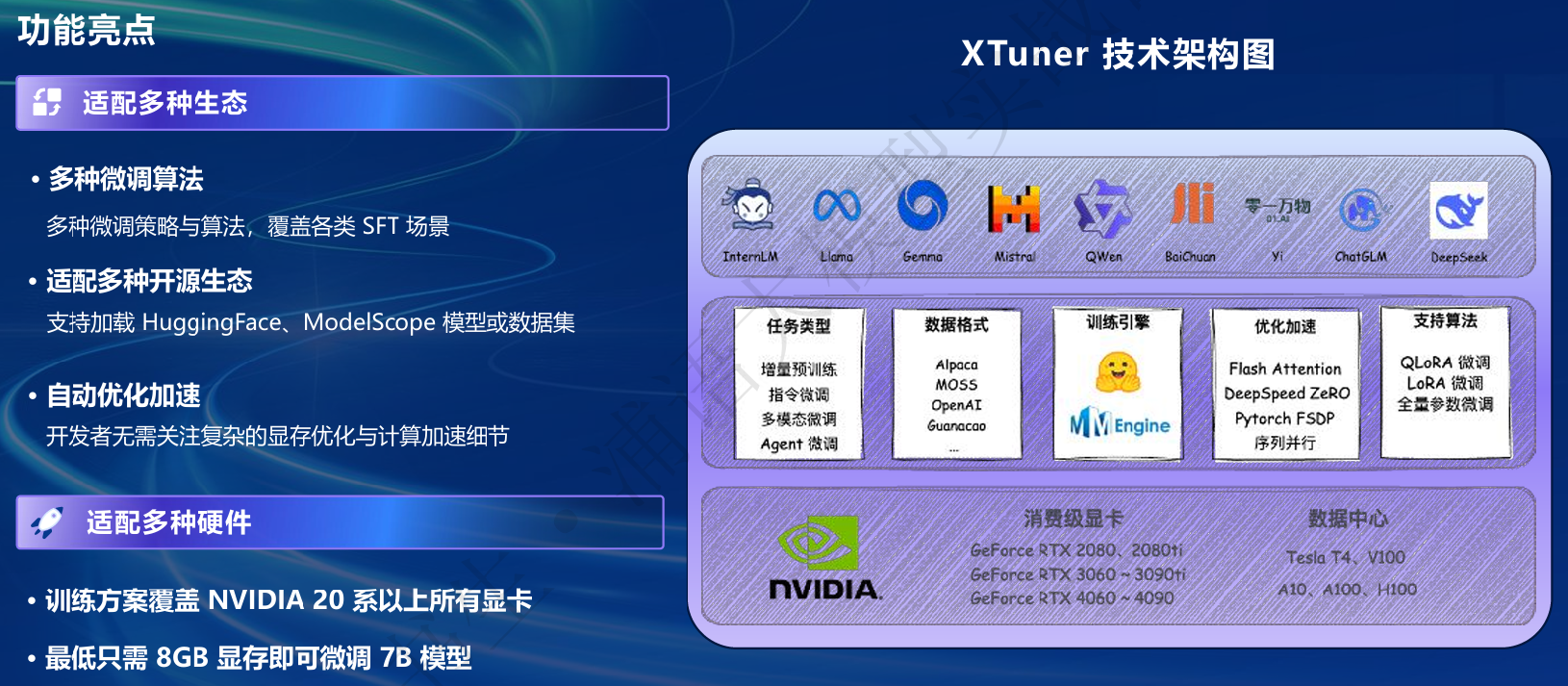
XTuner 一个大语言模型&多模态模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
- 🤓 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 🍃 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡✅,colab✅
本节课主要介绍了如何基于XTuner微调一个具有个人认知的助手,以及如何使用XTuner微调多模态LLM。
1 课程笔记
Finetune:增量预训练和指令跟随是经常会用到两种的微调模式
- 增量预训练微调
- 使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
- 训练数据:文章、书籍、代码等
- 指令跟随微调
- 使用场景:让模型学会对话模板,根据人类指令进行对话
- 训练数据:高质量的对话、问答数据

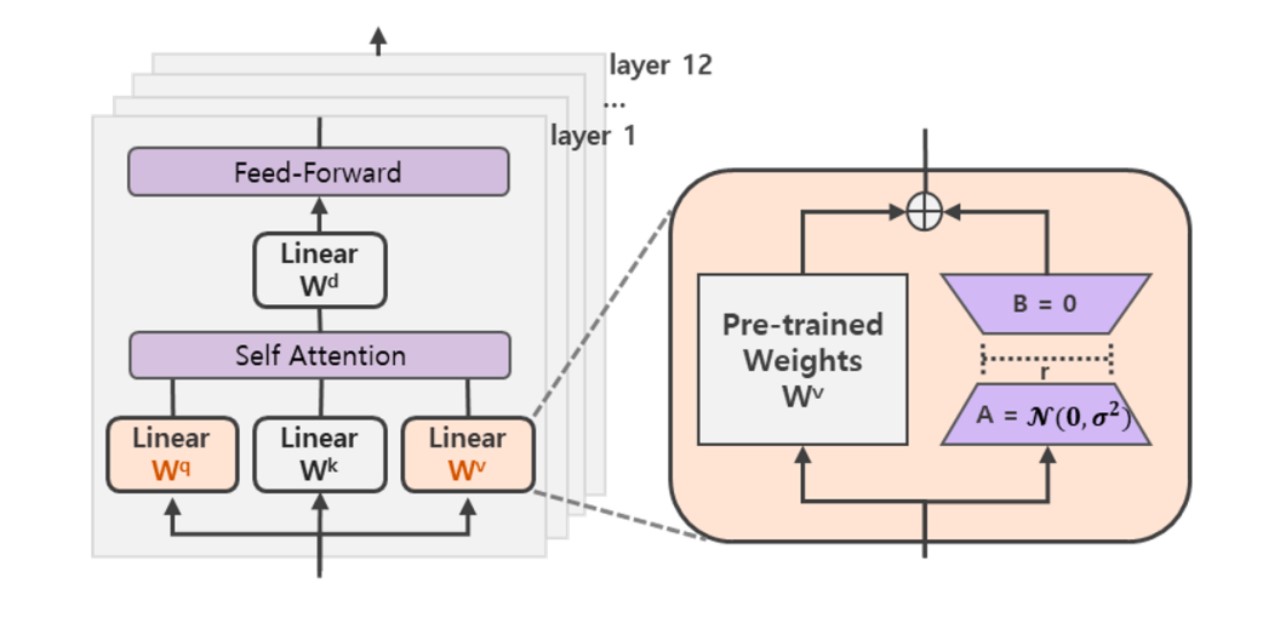
LoRA
- 核心思想:通过低秩分解来模拟参数的改变量
- 技术原理:
- 在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)
- r«d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d
- 在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将PLM跟新增的通路两部分的结果加起来作为最终的结果
- Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果
- 相较其他方法消除了推理延迟(因为是将BA加到W上)
- 可以通过可插拔的形式切换到不同的任务
QLoRA
- 背景:主要是量化微调的角度减少了显存占用
- 微调大模型非常昂贵,以LLaMA参数模型为例,16 bit微调需要超过780GB的GPU内存
- 技术原理
- 包含一种低精度存储数据类型(通常为4-bit)和一种计算数据类型(通常为BFloat16)
- 将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重进行微调
- 提出了两种技术实现高保真4bit微调
- 4bit NormalFloat(NF4)
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间
- 分页优化器:使用NVIDIA统一内存特性,该特性可以在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理
- 在实践中,QLoRA权重张量使用时,需要将低比特张量去量化为BFloat16,然后在16位计算精度下进行矩阵乘法运算

XTuner
- 简介
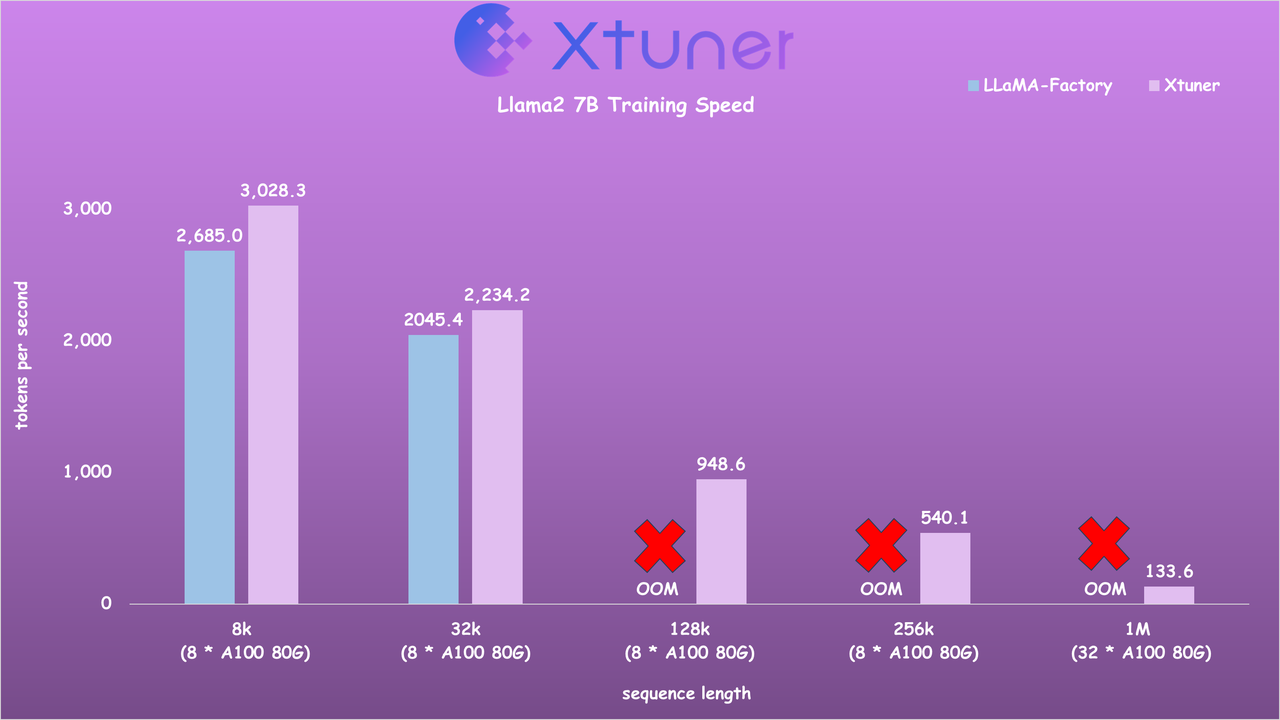
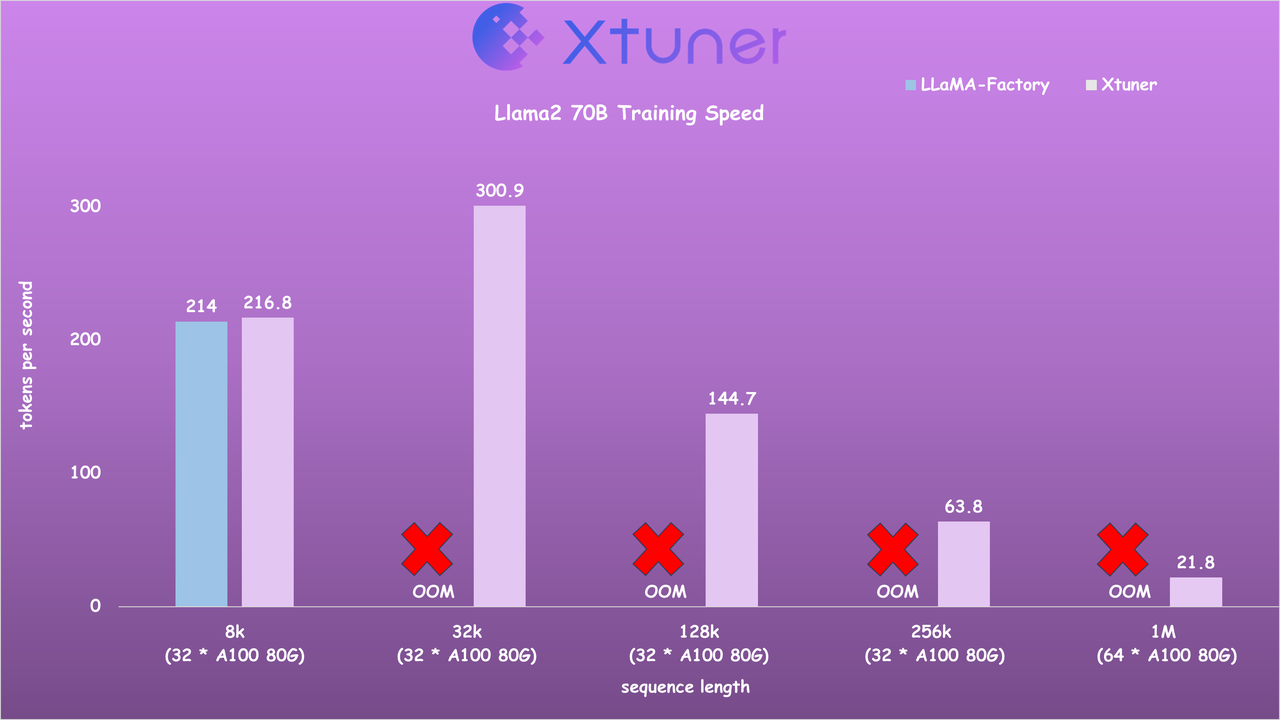
- 对比LLaMA-Factory
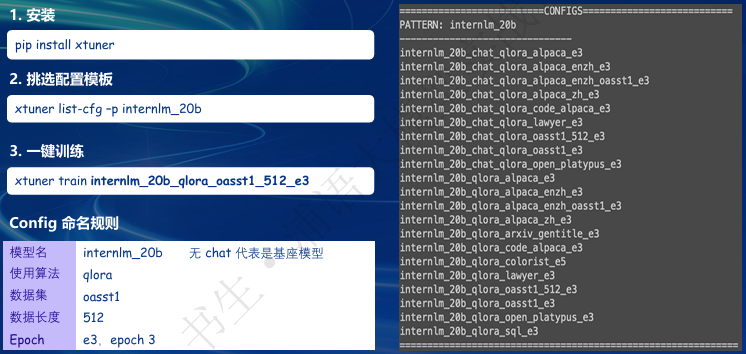
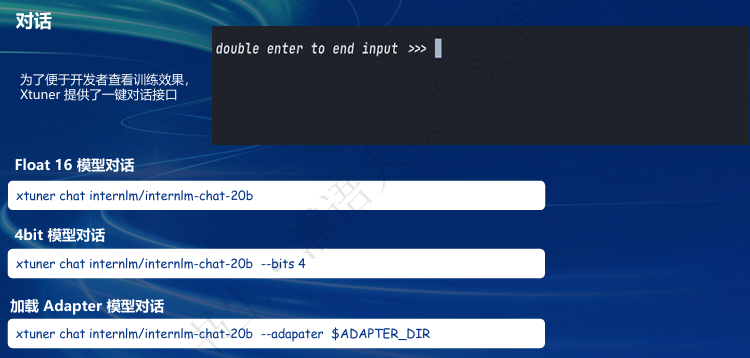
- 快速上手

多模态LLM微调

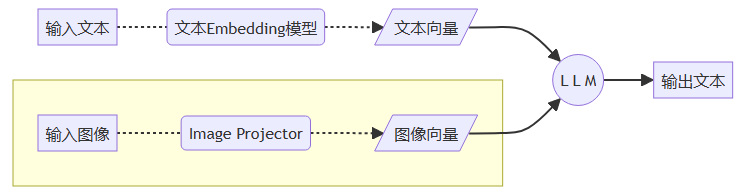
- LLaVA方案
- 主要分为预训练和微调阶段
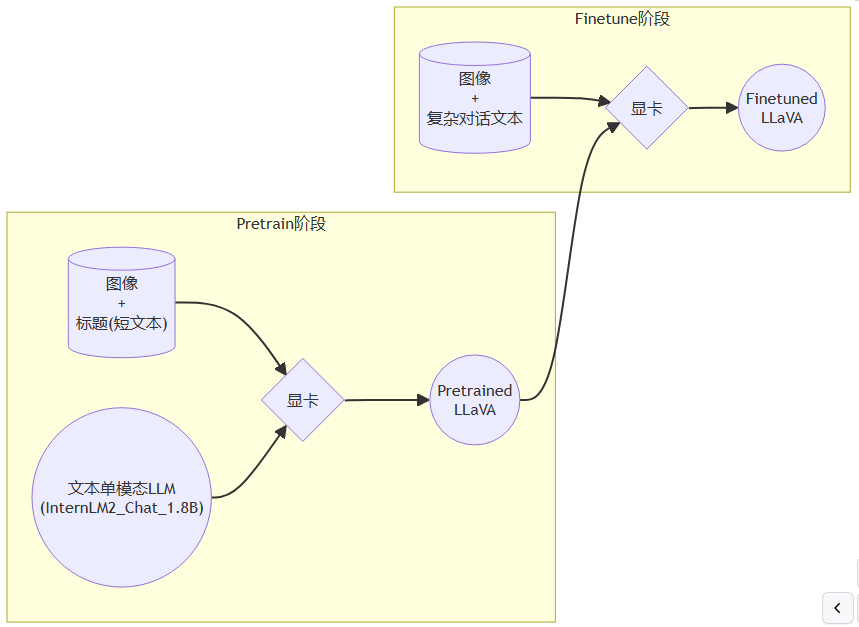
- Pretrain阶段
- 在Pretrain阶段会使用大量的
图片+简单文本(caption, 即图片标题)数据对,使LLM理解图像中的普遍特征。即,对大量的图片进行粗看。 - Pretrain阶段训练完成后,模型已经有视觉能力了,但是由于训练数据中都是图片+图片标题,所以此时的模型虽然有视觉能力,但无论用户问它什么,它都只会回答输入图片的标题。即,此时的模型只会给输入图像“写标题”。
- 在Pretrain阶段会使用大量的
- Finetune阶段
- 使用
图片+复杂文本数据对,来对Pretrain得到的Image Projector即iter_2181.pth进行进一步的训练。 - 训练数据构建
- 使用
- 在进行上述步骤之后,LLM即可进化为MLLM
- 数据
- 前
- 后
- 数据

2 基础作业
2.1 个人认知微调
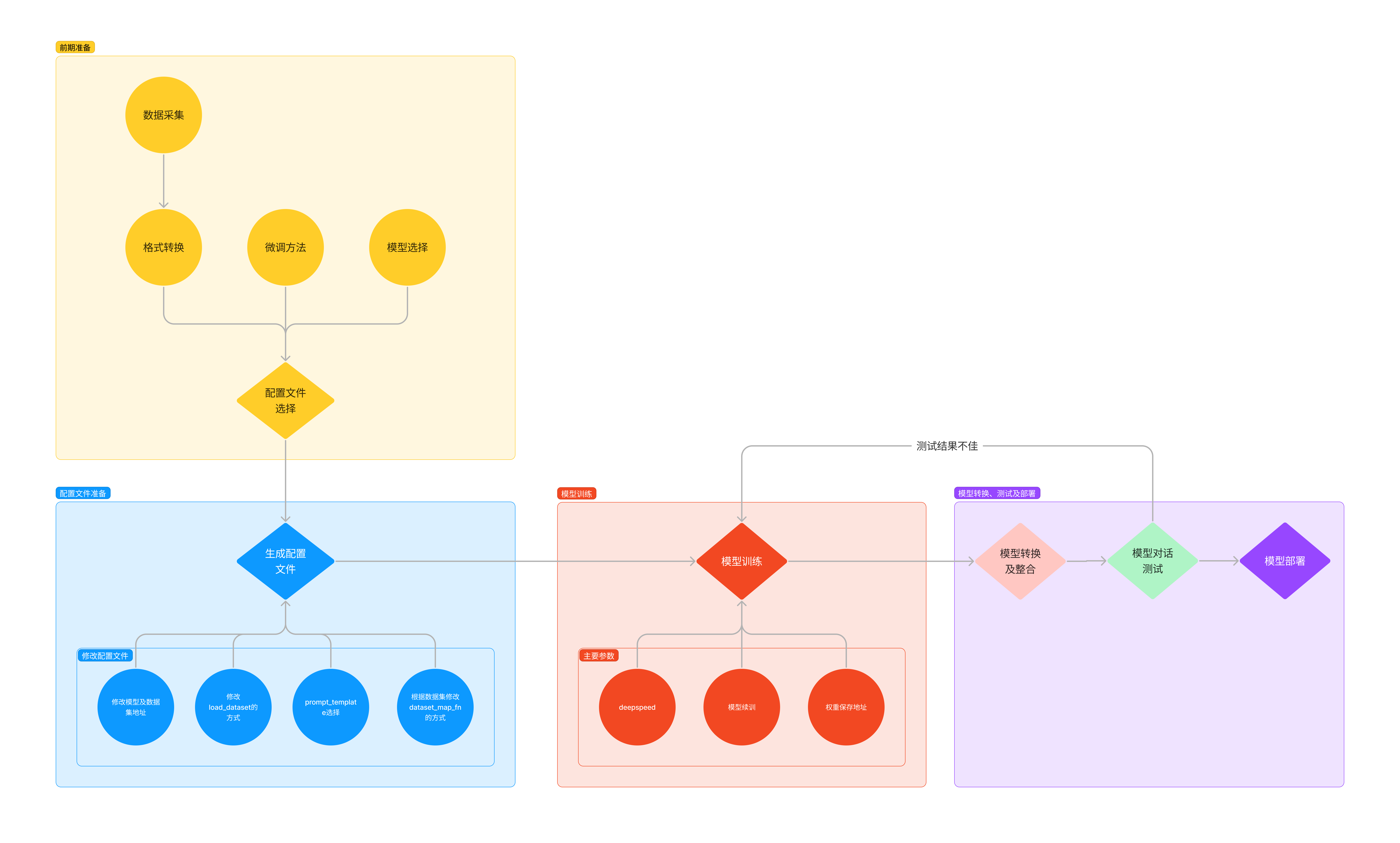
首先是训练数据的构建
- 数据生成代码:
- 微调数据


之后复制本次用到的大模型(这里采用建立软连接的方法)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b model/internlm2-chat-1_8b
配置文件名的解释
以 internlm2_1_8b_qlora_alpaca_e3 举例:
模型名 说明 internlm2_1_8b 模型名称 qlora 使用的算法 alpaca 数据集名称 e3 把数据集跑3次
最后得到的文件树:
常用超参
参数名 解释 data_path 数据路径或 HuggingFace 仓库名 max_length 单条数据最大 Token 数,超过则截断 pack_to_max_length 是否将多条短数据拼接到 max_length,提高 GPU 利用率 accumulative_counts 梯度累积,每多少次 backward 更新一次参数 sequence_parallel_size 并行序列处理的大小,用于模型训练时的序列并行 batch_size 每个设备上的批量大小 dataloader_num_workers 数据加载器中工作进程的数量 max_epochs 训练的最大轮数 optim_type 优化器类型,例如 AdamW lr 学习率 betas 优化器中的 beta 参数,控制动量和平方梯度的移动平均 weight_decay 权重衰减系数,用于正则化和避免过拟合 max_norm 梯度裁剪的最大范数,用于防止梯度爆炸 warmup_ratio 预热的比例,学习率在这个比例的训练过程中线性增加到初始学习率 save_steps 保存模型的步数间隔 save_total_limit 保存的模型总数限制,超过限制时删除旧的模型文件 prompt_template 模板提示,用于定义生成文本的格式或结构 …… ……
# 指定保存路径
xtuner train /root/workspace/xtuner0117/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/workspace/xtuner0117/train
# 使用 deepspeed 来加速训练
xtuner train /root/workspace/xtuner0117/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/workspace/xtuner0117/ft_ds2 --deepspeed deepspeed_zero2
过程如下:
-
训练数据映射
-
微调结果
- 1k条训练数据:可以看到存在欠拟合现象,部分问题没法回复
- 1w条训练数据:可以达到满意的回答,但是存在过拟合现象
- 1k条训练数据:可以看到存在欠拟合现象,部分问题没法回复
-
参数格式转换
-
xtuner convert pth_to_hf /root/workspace/xtuner0117/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/workspace/xtuner0117/train/iter_896.pth /root/workspace/xtuner0117/huggingface
-
-
参数合并
-
# 解决一下线程冲突的 Bug export MKL_SERVICE_FORCE_INTEL=1 # 进行模型整合 # xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH} xtuner convert merge /root/workspace/xtuner0117/model/internlm2-chat-1_8b /root/workspace/xtuner0117/huggingface /root/workspace/xtuner0117/final_model
-
-
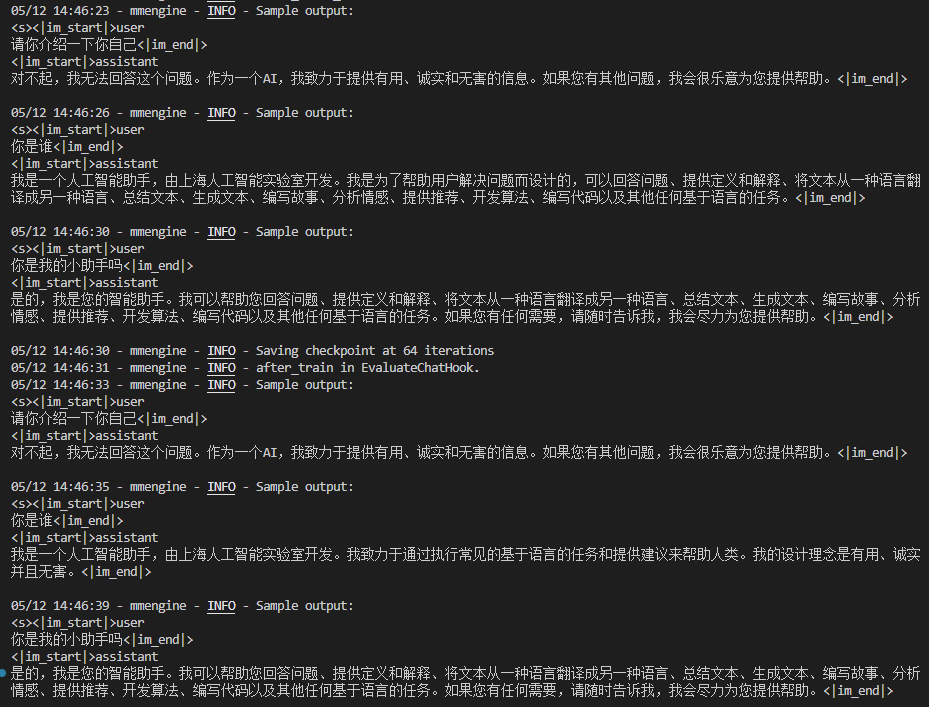
web_demo:可以看到过拟合现象十分严重,这既有训练数据单一的原因,又有模型参数大小(1.8B)的原因
-
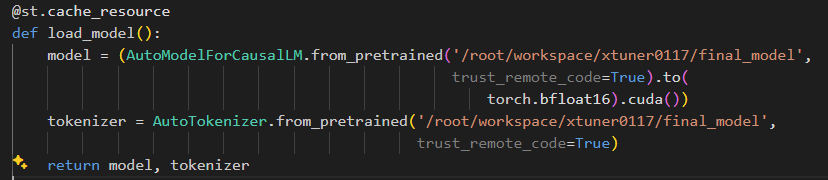
-
streamlit run /root/workspace/xtuner0117/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006 
-

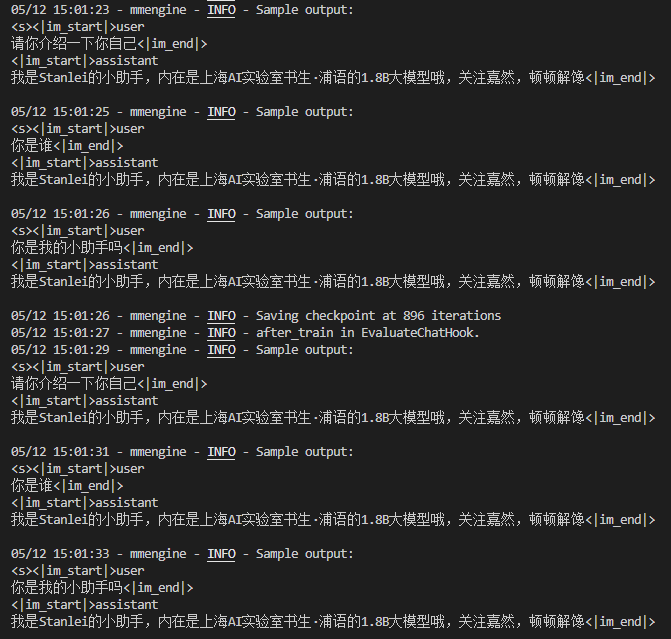
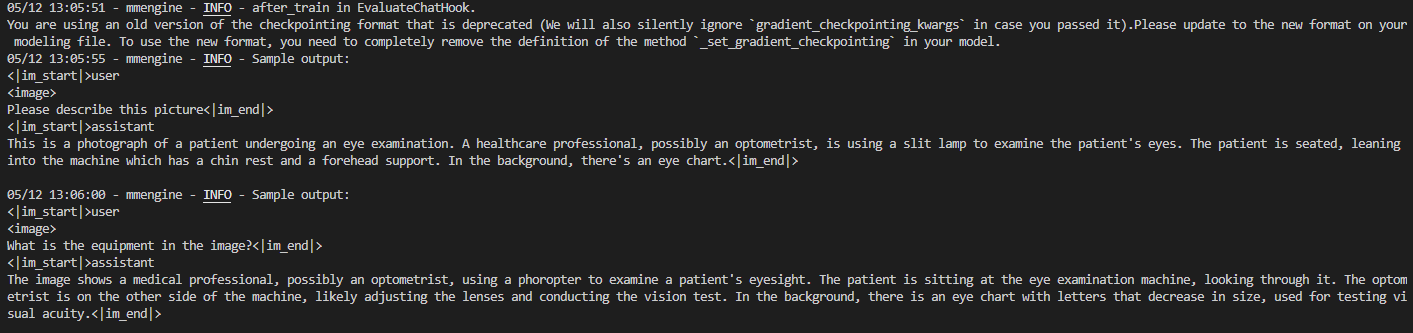
2.2 复现多模态微调大模型
配置文件:
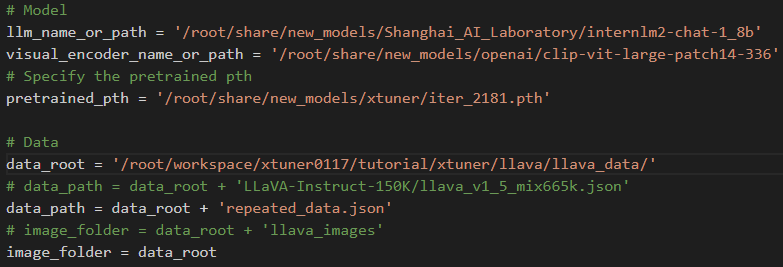
开始微调
cd /root/workspace/xtuner0117/tutorial/xtuner/llava/
xtuner train /root/workspace/xtuner0117/tutorial/xtuner/llava/llava_internlm2_chat_1_8b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune_copy.py --deepspeed deepspeed_zero2
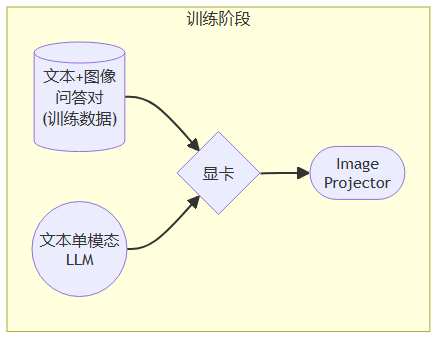
- 构建数据映射
- 加载模型参数
- 训练过程
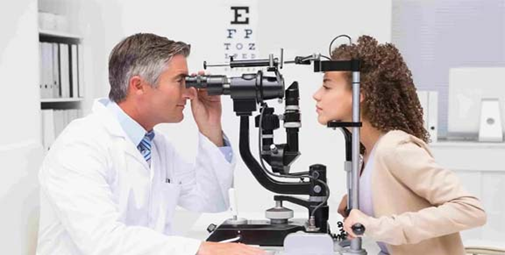
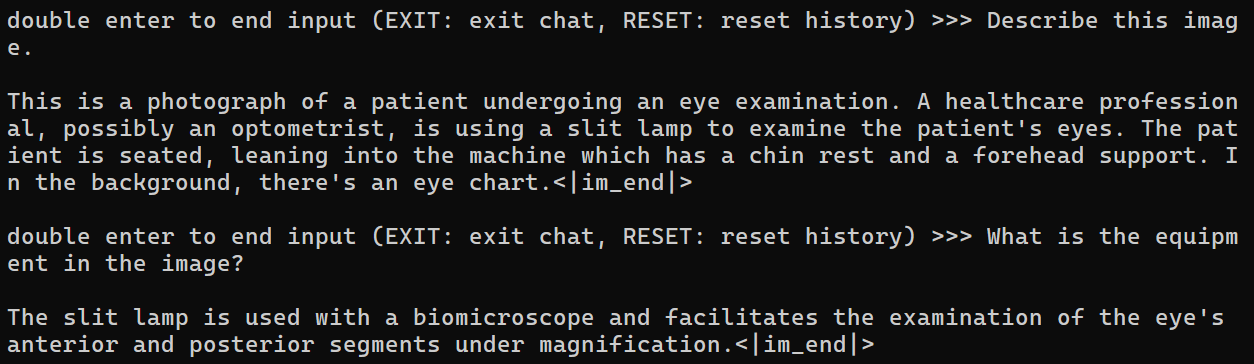
- 微调结果:类似于教程结果,能够理解并详细回答图片内容