0 课程背景
- 茴香豆:搭建你的 RAG 智能助理
- InternLM/Tutorial
- 主讲人:书生·浦语社区贡献者,北辰
在进行本次课程学习之前,本人已经尝试了诸多RAG框架,例如LangChain、LlamaIndex,在此介绍这两个框架的使用,可以看到所有的RAG框架在结构上都是类似的。
-
LangChain:
-
RAG结构
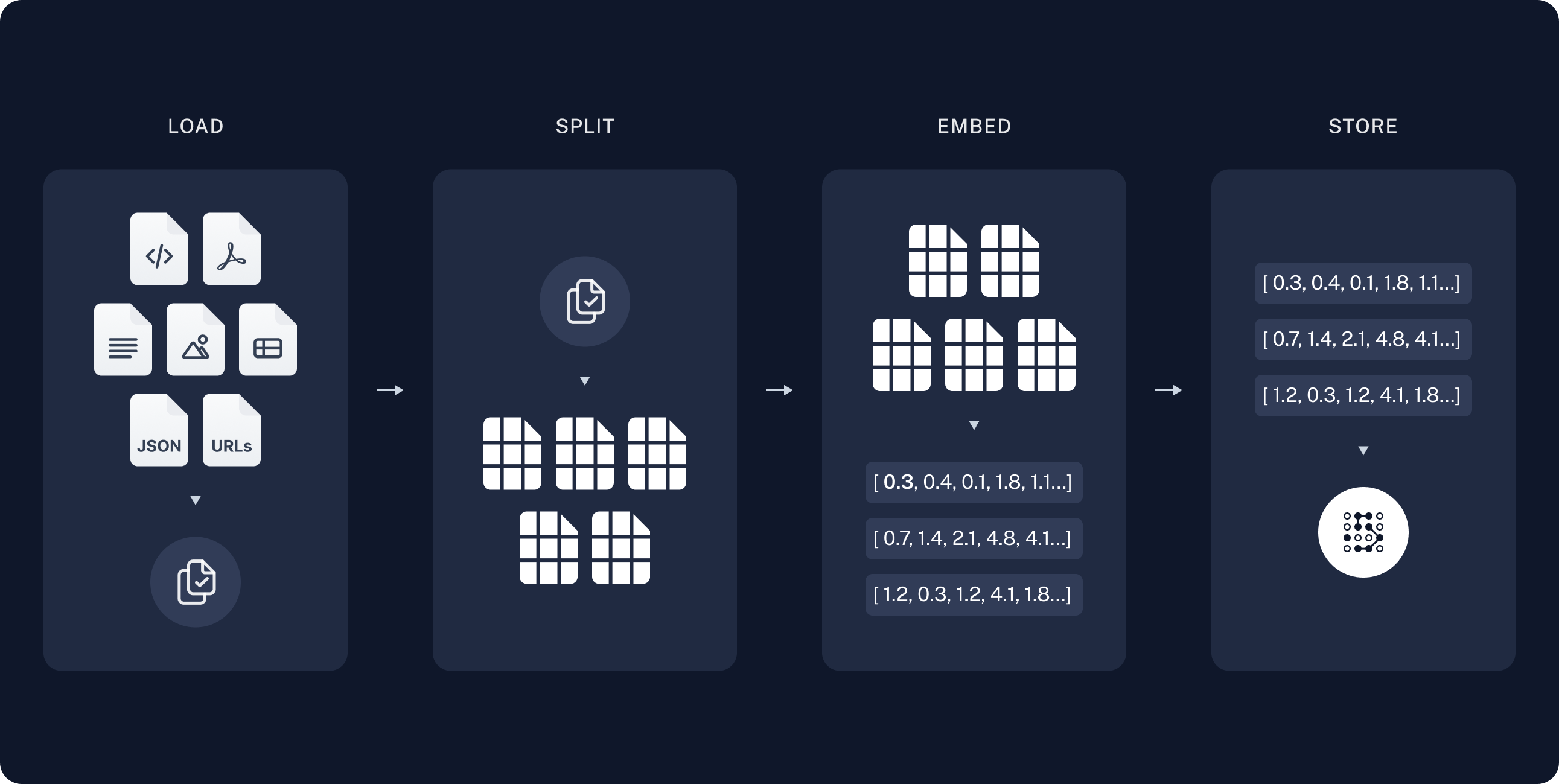
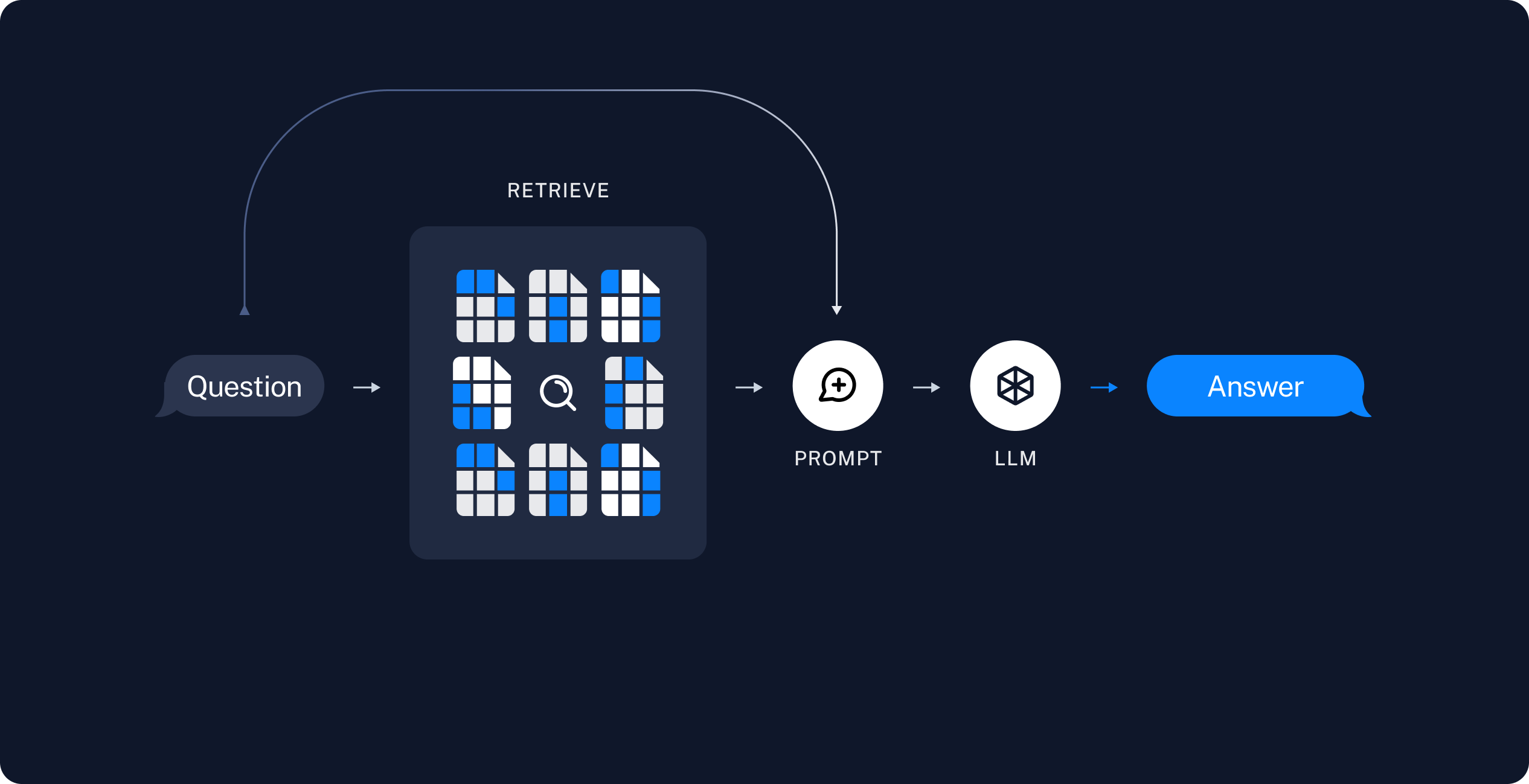
- 索引:从知识源获取数据并对其进行索引的pipeline
- 检索和生成:在运行时接受用户查询并从索引中检索相关数据,然后将其传递给模型
- 索引:从知识源获取数据并对其进行索引的pipeline
-
示例代码
-
文档加载与分块
-
import bs4 from langchain_community.document_loaders import WebBaseLoader # Only keep post title, headers, and content from the full HTML. bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), bs_kwargs={"parse_only": bs4_strainer}, ) docs = loader.load() -
from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True ) all_splits = text_splitter.split_documents(docs)
-
-
存储
-
使用Chroma向量数据库
-
from langchain_chroma import Chroma from langchain_openai import OpenAIEmbeddings vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
-
-
检索与生成
-
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6}) retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?") -
from langchain_core.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template) rag_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | custom_rag_prompt | llm | StrOutputParser() ) rag_chain.invoke("What is Task Decomposition?")
-
-
-
-
LlamaIndex:
-
Load data and build an index
-
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings from llama_index.embeddings.ollama import OllamaEmbedding from llama_index.llms.ollama import Ollama documents = SimpleDirectoryReader("data").load_data() # nomic embedding model Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text") # ollama Settings.llm = Ollama(model="llama3", request_timeout=360.0) index = VectorStoreIndex.from_documents( documents, )
-
-
Query
-
query_engine = index.as_query_engine() response = query_engine.query("What did the author do growing up?") print(response)
-
-
1 课程笔记
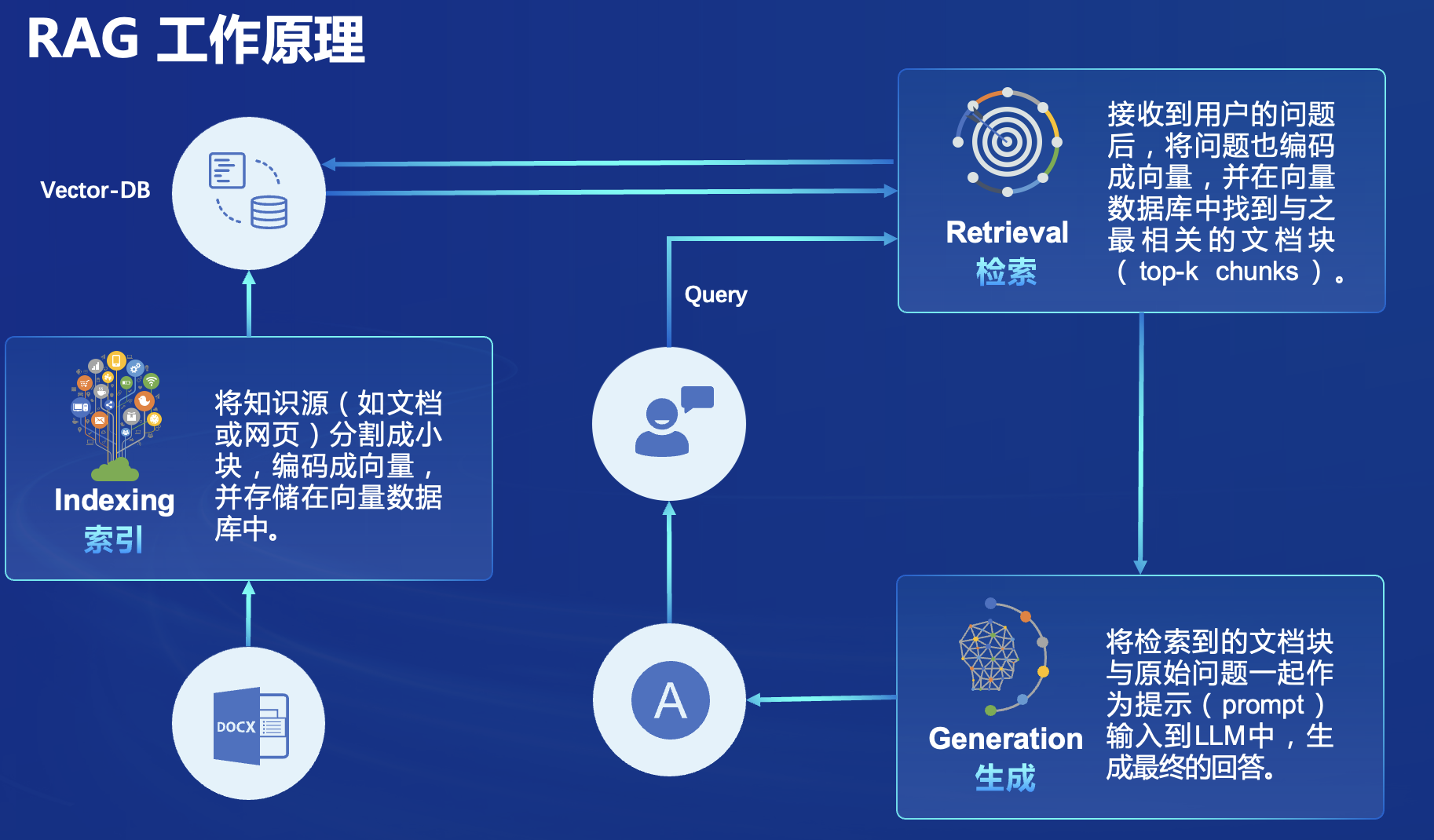
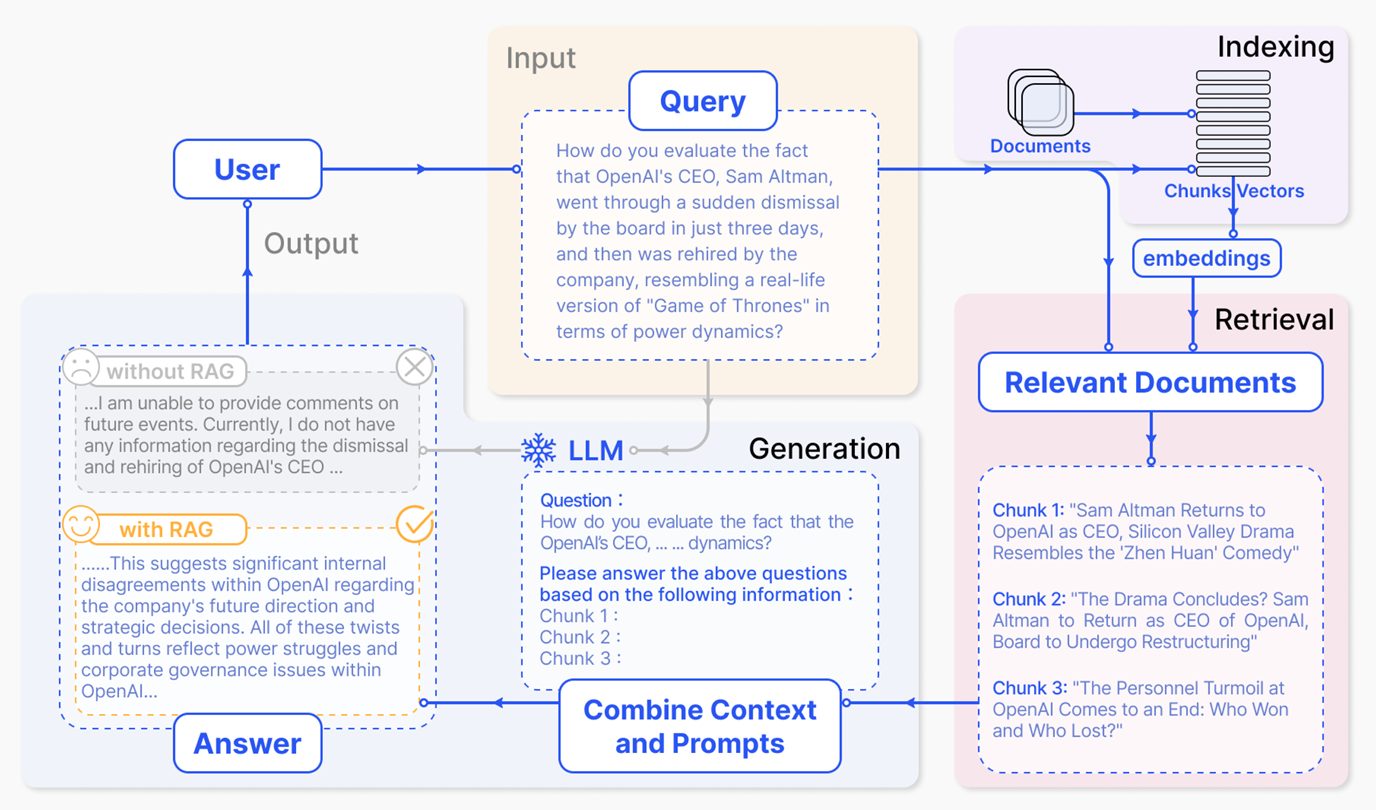
首先介绍什么是RAG:
- RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
- RAG能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。
- RAG流程示例
- 常见优化方法
- 对比RAG和微调


之后介绍HuixiangDou
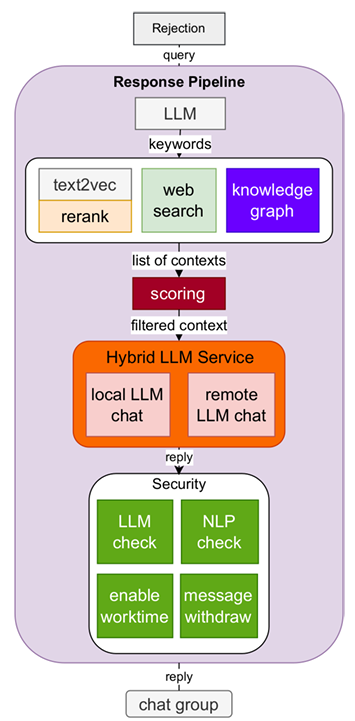
- 一个基于 LLM 的群聊知识助手
- 设计拒答、响应两阶段pipeline应对群聊场景,解答问题同时不会消息泛滥
- 成本低至1.5G 显存,无需训练适用各行业
- 提供一整套前后端web、android、算法源码,工业级开源可商用
- 支持的模型
- 工作流
2 基础作业
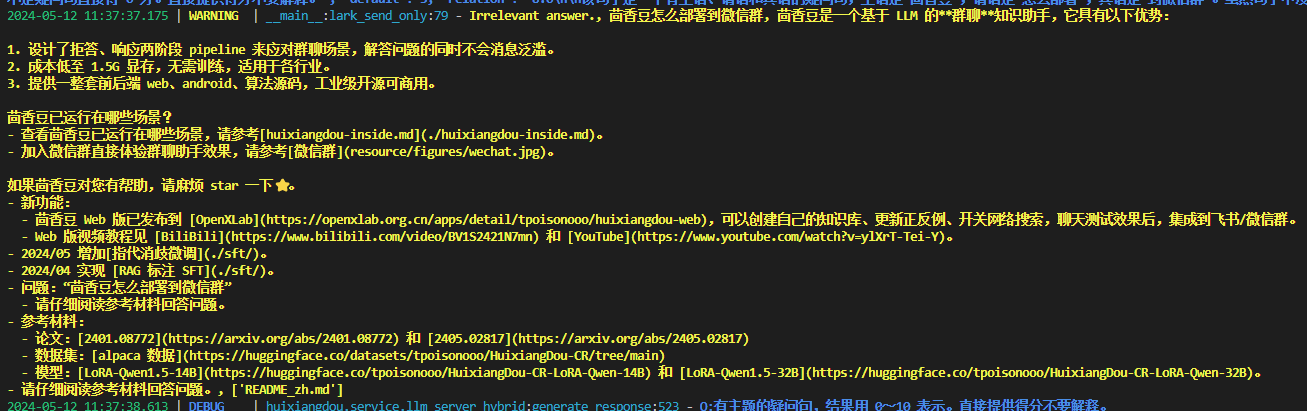
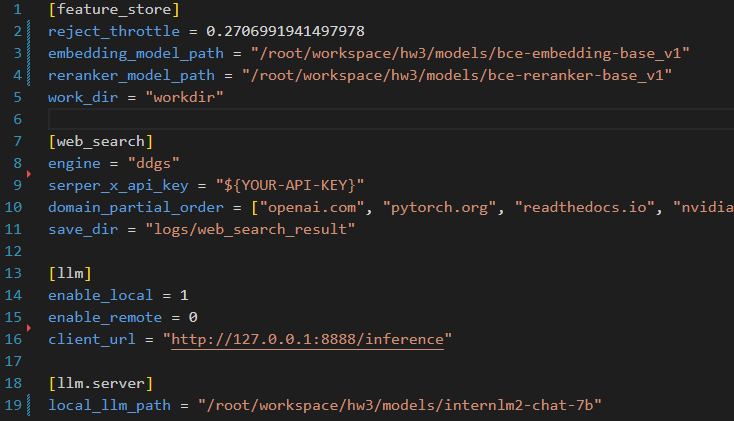
参考教程文档,我搭建了茴香豆技术助手,首先是更改config.ini
之后填入问题”茴香豆怎么部署到微信群?”:

运行结果如下:
茴香豆的回答如下:
- 主题提取
- 文档检索
- 相似度评分
- 提问
- 大模型回复
- 网络检索(由于没有token,最后我在
config.ini中取消了网络检索) - 最终回答(因为知识库里没有对应答案,也没有联网搜索,最后得到的是
Irrelevant answer)