0 课程背景
- 书生·浦语大模型全链路开源体系
- InternLM/Tutorial
- 主讲人:上海人工智能实验室青年科学家,陈恺
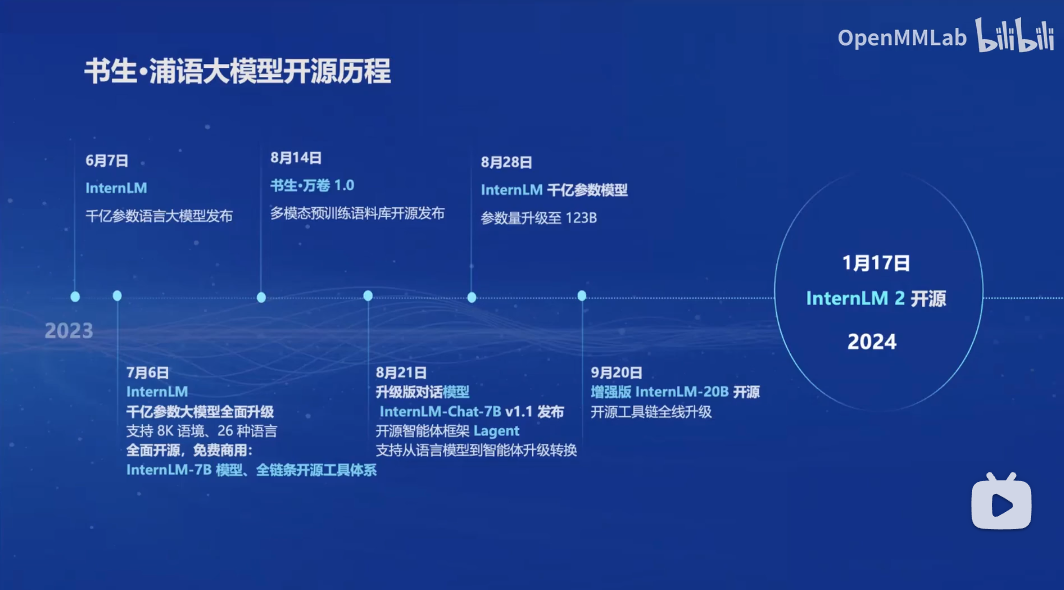
0.1 开源历程
0.2 InternLM大模型家族
主要包括7B和20B两种参数大小的模型,分别包括InternLM2、InternLM2-Base、InternLM2-Chat三个不同场景下的版本。

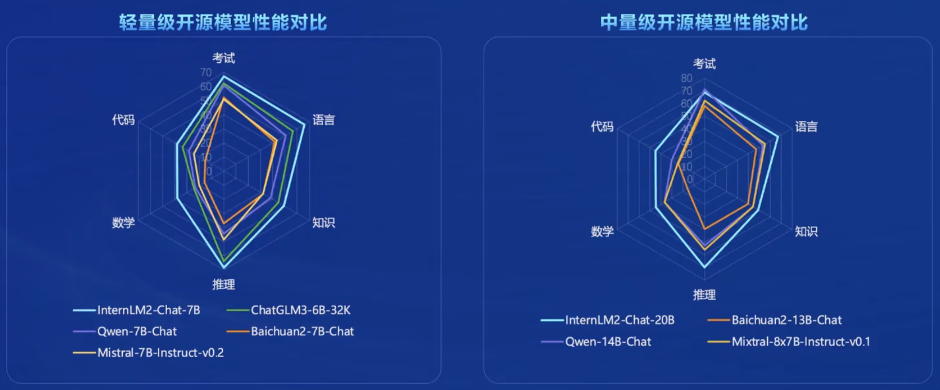
0.3 性能对比
2 模型到应用
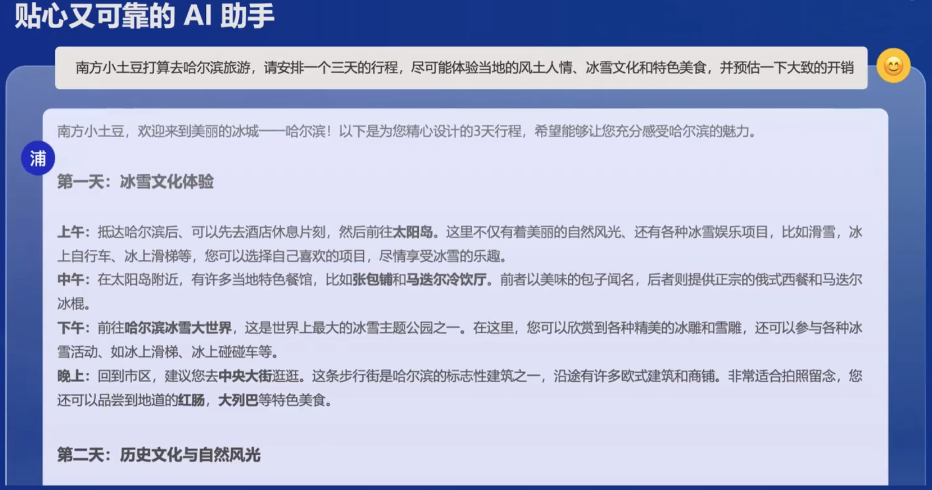
大模型的训练是一件非常耗费资源的事情,如何将模型落地是最终都需要面临的问题。浦语大模型的应用主要表现在以下几个方面:
- 原生能力
- AI助手
- 心理咨询
- 艺术创作:剧本撰写
- 数学计算
- AI助手
- 工具调用能力
- 代码解释器
- 文档阅读
- 表格数据分析
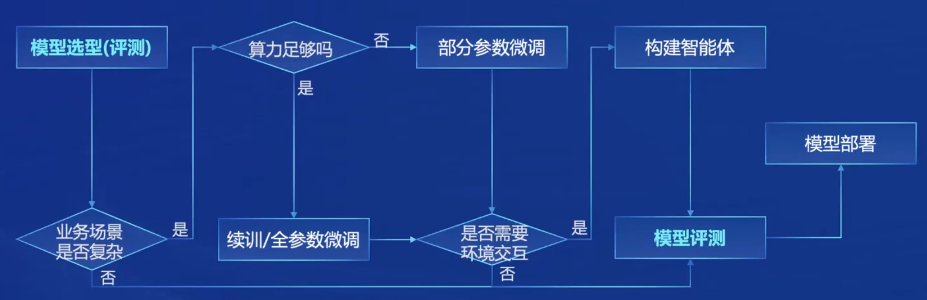
- 从模型到应用



3 比较重要的开源内容
3.1 数据
获取来源:数据集-OpenDataLab

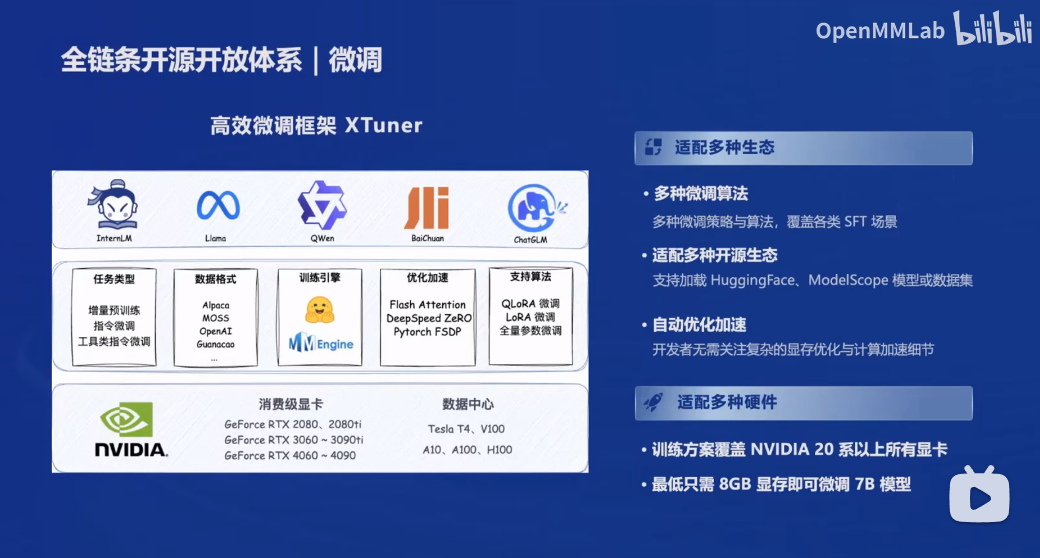
3.2 微调框架
支持当前主流开源大模型:国内的如InternLM、QWen、Baichuan、ChatGLM,国外的如LLaMA。
3.3 评测
提供了OpenCompass评测体系:OpenCompass
- 大模型评测工具链
- 大模型榜单:


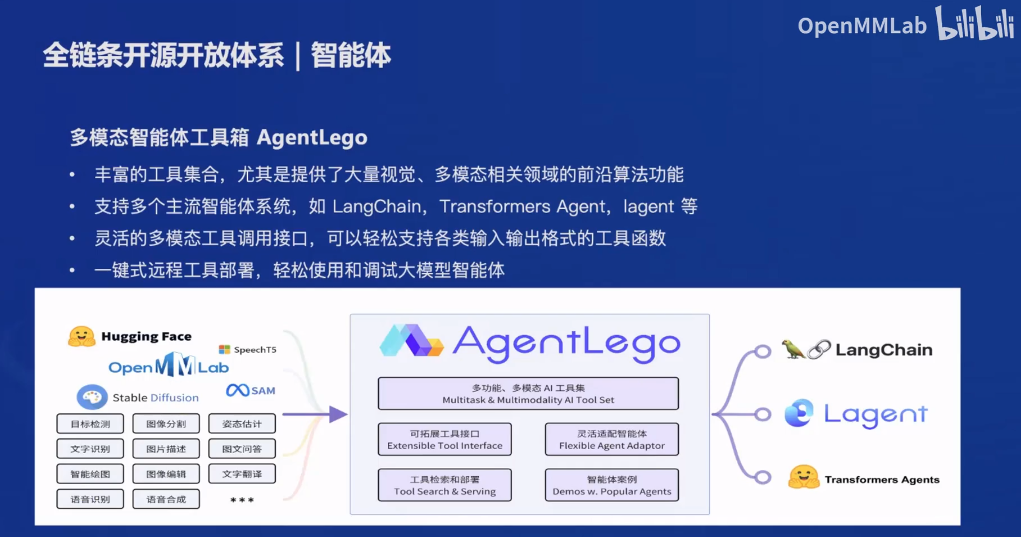
3.4 应用
提供了轻量级智能体框架Latent和多模态智能工具箱AgentLego

4 模型细节
模型架构图

4.1 预训练
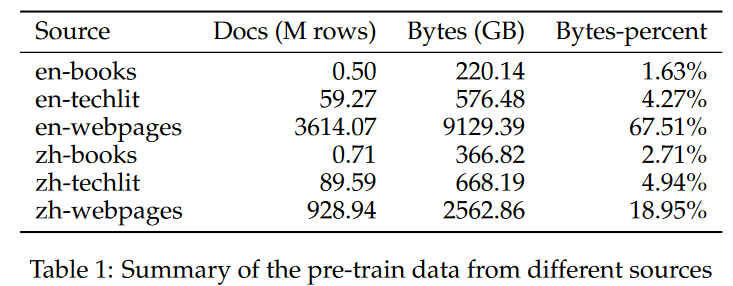
数据集
- 文本数据集
- 来源
- 数据清洗pipeline
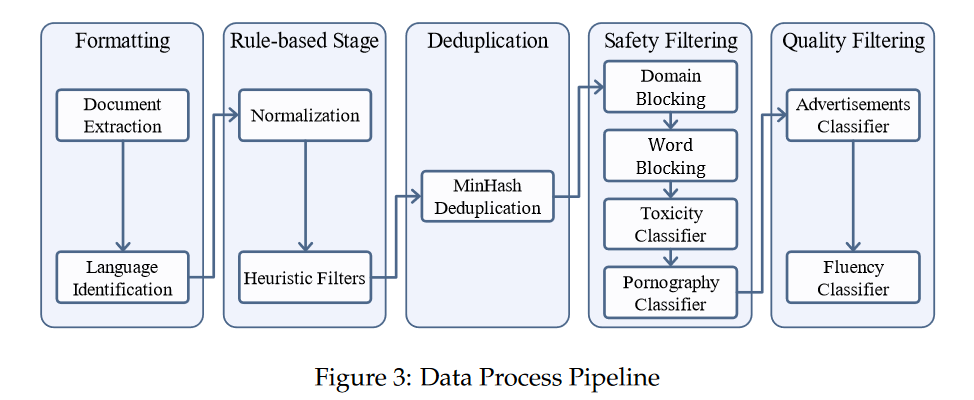
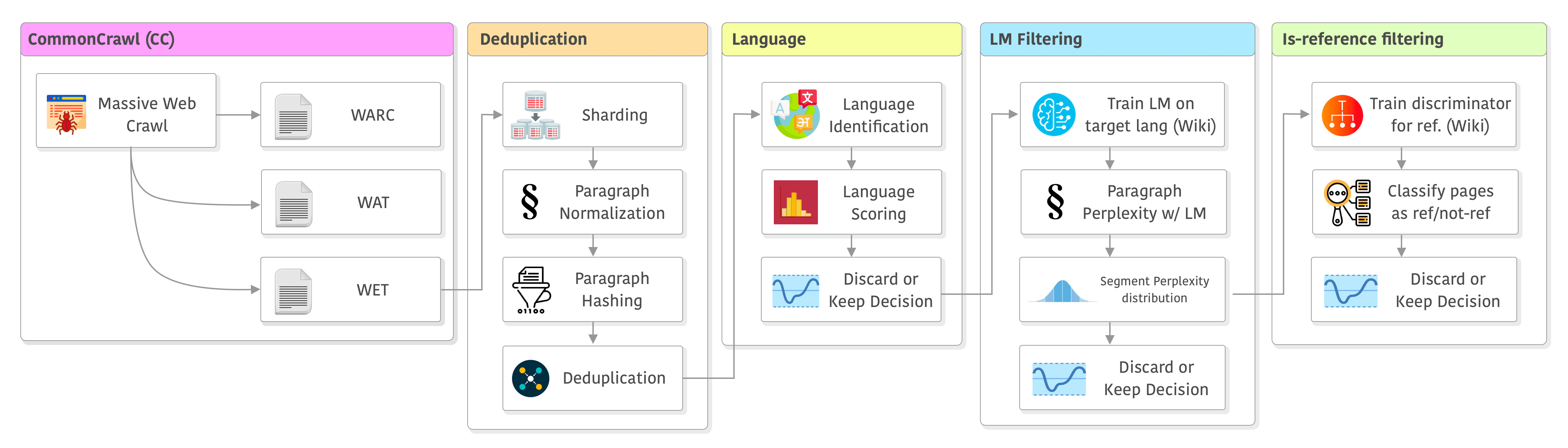
- 比较类似LLaMA的数据预处理流程Large language model data pipelines and Common Crawl (WARC/WAT/WET),可以对比起来看
- 数据爬取与保存
- 数据去重
- 文本语言识别与过滤
- 质量过滤
- 进一步过滤
- 来源
- 代码数据集
- 提高InternLM2的编程能力
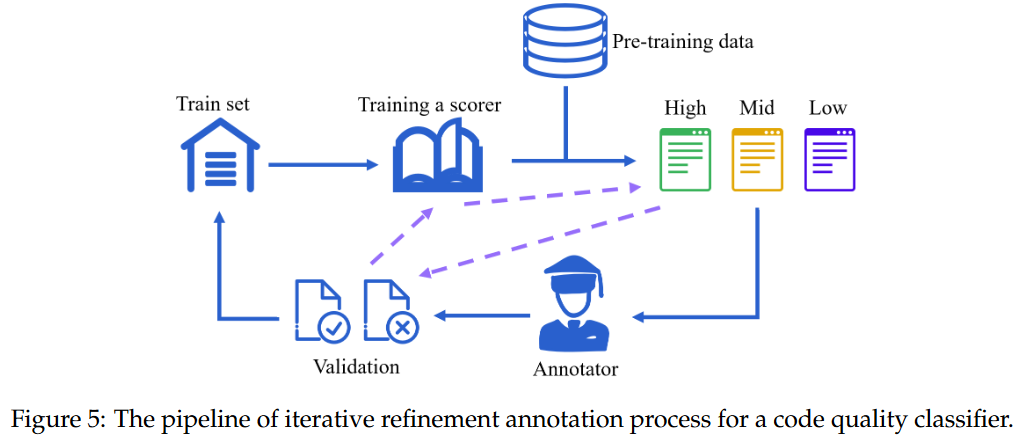
- 长上下文数据集
- 为了增强InternLM2的书籍摘要、长对话能力,以及能够处理涉及复杂推理步骤的任务
训练细节
- Tokenization
- 4k Context Training
- Long Context Training:大约32k的上下文窗口
- 特定能力训练:在特定能力的数据集上进行训练,以提高推理、数学问题解决和知识记忆能力
4.2 对齐
- 监督微调(SFT)
- RLHF
- 提出了Conditional OnLine RLHF(COOL RLHF)方法
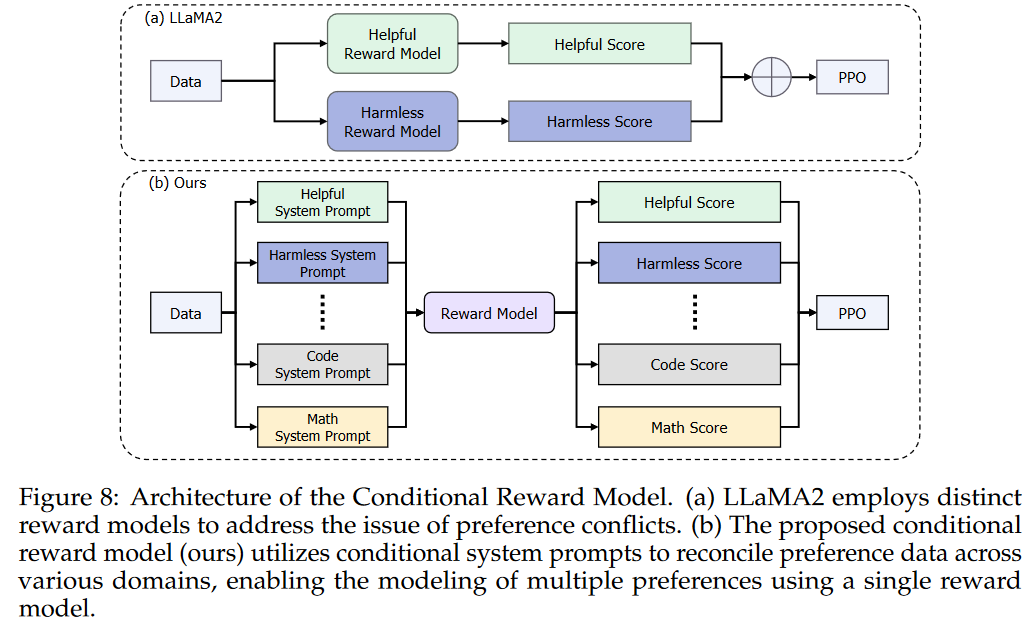
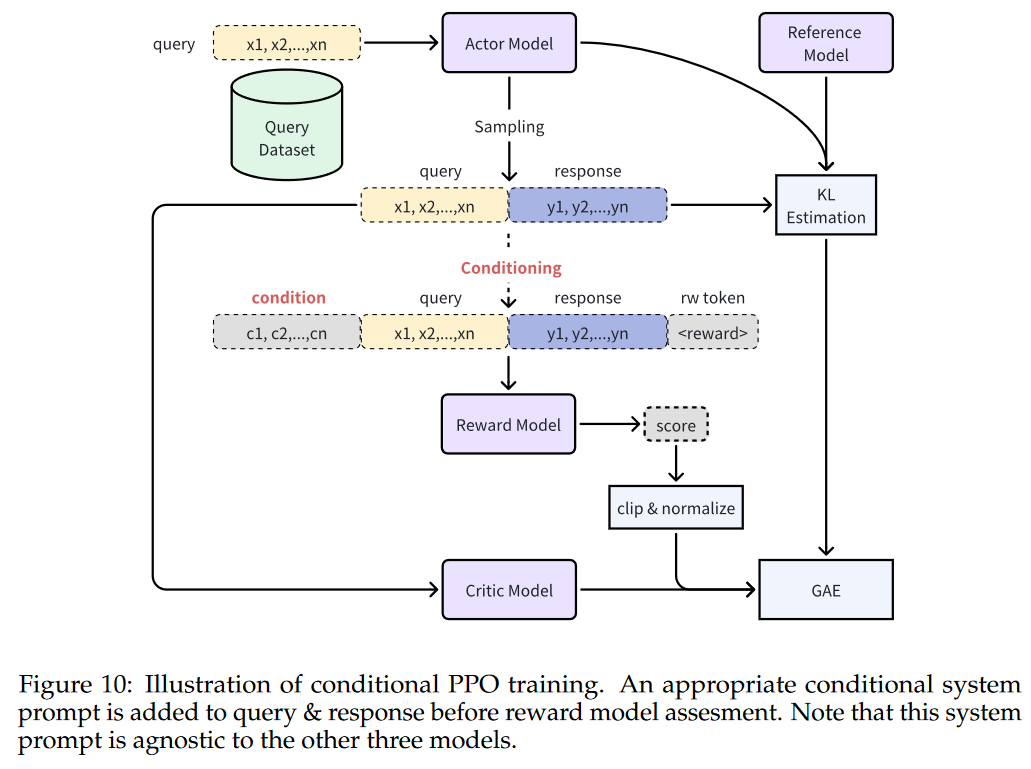
- Long-Context Finetuning
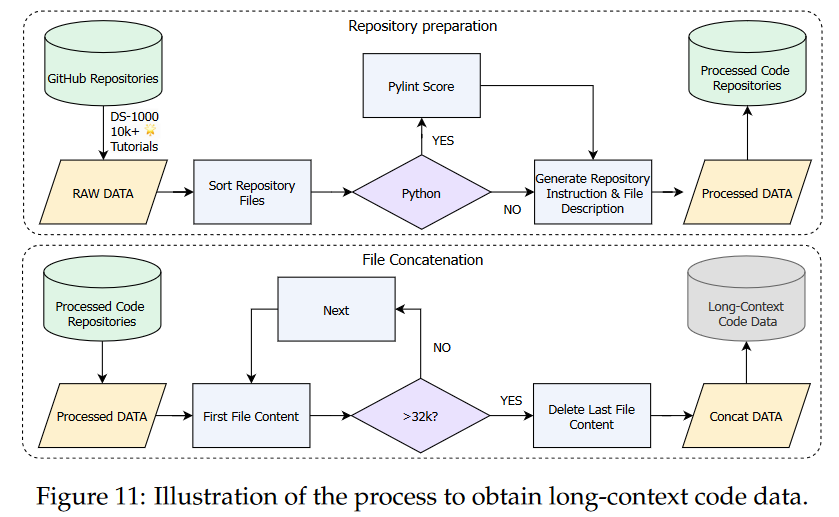
- 为了增强InternetLM2的数据分析能力,使用GitHub上超过10000star的repo
- 长上下文代码数据不仅提高了LLM的长上下文能力,而且提高了代码能力
- Tool-Augmented LLMs
- 通用工具调用
- 代码解释器
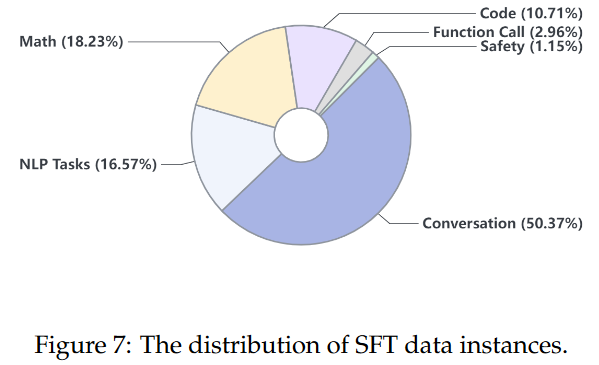
4.3 评估
主要包括下游任务评估和对齐评估的benchmark和结果,目前只列出评估任务,之后根据时间会尽可能补充benckmark和数据集。
下游任务
- comprehensive examinations
- language and knowledge
- reasoning and mathematics
- multiple programming language coding
- long-context modeling
- tool utilization.
对齐
- English Subjective Evaluation
- Chinese Subjective Evaluation
- Instruct Following Evaluation
- Ablation Study of Conditional Reward Model